计算机中的编码方式(计算机编码是如何编的)
导语:一文读懂让人崩溃的编码问题,计算机如何存储中文
我相信任何一位中国开发者,都绝对遇到过乱码这个问题。中文,特别是繁简中文的转换出现乱码是家常便饭。为何会出现乱码?到底计算机是如何存储我们的中文的?今天就让我们一起来深入了解一下:
字节、位、二进制
要搞清楚编码问题,必不可少需要对计算机数据存储原理的认识。我们都知道计算机只存储二进制,也即0和1。那么机器又是如何将我们人类可以识别的文字转换为0和1存起来呢?
大家还记得自己刚编程入坑时接触的ASCII码吗?可能很多人学了之后也不清楚ASCII码是干嘛的?它其实说白了就是一个人为制定的字符到数值的一个映射表。
比如,字符‘A’对应的数字是65,65是十进制表示方法,将它转换为二进制就是01000001;好,现在我们将A通过这种映射关系转换为了二进制01000001,那么怎么存呢?这又牵扯到字节和位的概念了。
字节是计算机中数据处理的基本单位。计算机中以字节为单位存储和解释信息,规定一个字节由八个二进制位构成,即1个字节等于8个比特(1Byte=8bit)。一个位可以存一个状态码也即0和1;而一个英文字符是一个字节,所有从字符A到存储关系就是这样的:

中文字符
了解了英文字符的存储,那么中文字符也按照英文那样存呗;但是,咱们中文博大精深,中文具体有多少个字符我是不知道,但据了解有近十万个。如果一个中文字符只是一个字节,也即是8位的话,根本不够用,因为一个字节最多自能表示到127(第一位为符号位,所以剩下七位是有效的用来表示数字),即每一位都是1,那么就是01111111,十进制为127,而0到127全部被ASCII码占用了。十万中文字,127对它来说实在是不够看,并且全世界那么多中语言,那么多字符,怎么办呢?这时候万国码Unicode就面世了。
Unicode是属于编码字符集(CCS)的范围。Unicode所做的事情就是将我们需要表示的字符表 中的每个字符映射成一个数字,这个数字被称为相应字符的code point码点。例如“严”字在Unicode中对应的码点是U+0x4E25。同样,将之转换为二进制:100111000100101,很显然,一个字节肯定不够存,我们需要两个或者更多个字节来存储,那么问题又来了,到底是用两个字节还是三个字节亦或是更多字节呢?聪明的人就站出来说了,我们不需要定死,我们用变长的字节。如果使用了变长的字节表示一个字符,那就必须要知道是几个字节表示了一个字符,要不然计算机可没 那么聪明。下面介绍一下最常用的UTF-8。
UTF-8 的编码规则很简单,只有二条:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。
2)对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
下表总结了编码规则,字母x表示可用编码的位。
Unicode符号范围 | UTF-8编码方式 (十六进制) | (二进制) ----------------------+--------------------------------------------- 0000 0000-0000 007F | 0xxxxxxx
0000 0080~0000 07FF | 110xxxxx 10xxxxxx
0000 0800~0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000~0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
跟据上表,解读 UTF-8 编码非常简单。如果一个字节的第一位是0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,则这个字符就需要占用多少个字节。
例如:严的 Unicode 是4E25(100111000100101),根据上表,4E25处(0000 0800 - 0000 FFFF)的范围,因此”严“的 UTF-8 编码需要三个字节,即格式是1110xxxx 10xxxxxx 10xxxxxx。从严的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。于是得到,严的 UTF-8 编码是11100100 10111000 10100101。
所以用图示表示“严”从字符到计算机存储是这样的:
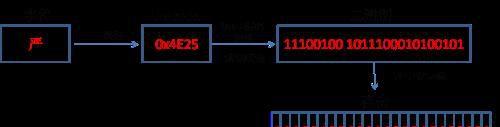
所以,以后别再说一个中文字符就是两个字节了;也别再说Unicode和UTF-8都是编码方式了。
END
手KEY不易,希望大家多多支持小编,点个关注~~~持续分享更多编程小知识;
免责声明:本站部份内容由优秀作者和原创用户编辑投稿,本站仅提供存储服务,不拥有所有权,不承担法律责任。若涉嫌侵权/违法的,请反馈,一经查实立刻删除内容。本文内容由快快网络小思创作整理编辑!