形象理解贝叶斯定理是什么(形象理解贝叶斯定理的应用)
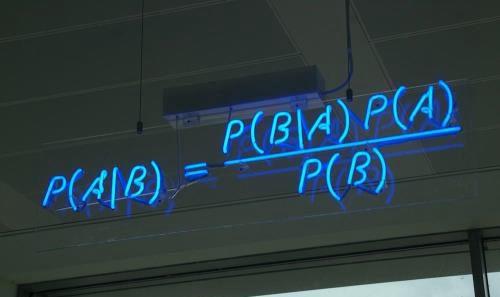
导语:形象理解贝叶斯定理
理解概率概念对于机器学习工程师或数据科学专业人员来说是必须的。许多数据科学挑战性问题的解决方案本质上是从概率视角解决的。因此,更好地理解概率将有助于更有效地理解和实现这些算法。
每当你阅读任何概率书、博客或论文时,大多数时候你会发现这些书中的讲解太过理论化。据研究,65%的人是视觉学习者。以图形方式理解定理和证明是一种可视化信息和数据的有效方式,而且不仅以可视方式呈现数据已被证明长期有效。因此,本文以可视方式透彻展示、讲解概率概念。
本文安排如下:
1. 什么是条件概率?2. 总概率定律3. 贝叶斯定理4. 贝叶斯定理的应用什么是条件概率?根据维基百科, 条件概率是一个事件概率依赖于另一个事件(已然发生)的度量,假设(通过假设、推定、断言或证据)另一个事件发生的概率,表示为P(A / B)。
现在让我们尝试通过一种新的方法在视觉上解释它。
条件概率图
让我们假设我们在START的时间线内开始观察。P(A)表示在我们开始观察时间线之后发生事件A的概率。在A之后还有可能发生另一个事件B,并且其几率由P(B | A)表示。
由于两个事件都是连续发生的,所以整个时间线出现的概率(即A和B都发生,B发生在A之后)是
P(A)·P(B | A)
由于我们正在考虑A和B都发生的概率,它也可以解释为P(A∩B)
交叉规则(A∩B)
P(A∩B)= P(A)·P(B | A)
这里P(B | A)被称为条件概率,因此可以简化为
P(B | A)= P(A∩B)/ P(A),假设P(A)≠0
请注意,上述情况的前提是,事件序列发生且彼此相互依赖。也有可能A不影响B,如果是,则这些事件彼此独立并称为独立事件。
独立事件
在独立事件的情况下,A发生的几率不会影响B发生的几率。
P(B | A)= P(B)
总概率定律总概率定律将计算分为不同的部分。它用于计算事件的概率,该事件与前一事件之前发生的两个或多个事件相关。
太抽象了?让我们尝试一种视觉方法
总概率图
设B是可以在任何" n "个事件(A1,A2,A3,...... ...... An)之后发生的事件。如上所定义P(Ai∩B)= P(Ai)⋅P(B | Ai)∀i∈[1,n]
事件A1,A2,A3,...... A是相互排斥的,不能同时发生,我们可以通过A1或A2或A3或......或An到达B. 因此,用和的表达如下:
P(B)= P(A1∩B)+ P(A2∩B)+ P(A3∩B)+ ...... + P(An∩B)
进而:
P(B) = P(A1)·P(B | A1)+ P(A2)·P(B | A2)+ ...... + P(An)·P(B | An)
上述表达式称为总概率规则或总概率定律。
贝叶斯定理贝叶斯定理是一种基于某些概率的先验知识来预测起源或来源的方法
我们已经知道P(B | A)= P(A∩B)/ P(A),假设两个相关事件的P(A)≠0。有没有想过P(A | B)=?,从语义上说它没有任何意义,因为B发生在A之后,时间线无法逆转(即我们不能从B向上行进到START)
数学上我们根据条件概率知道
P(A | B)= P(B∩A)/ P(B),假设P(B)≠0
P(A | B)= P(A∩B)/ P(B),P(A∩B)= P(B∩A)
我们知道
P(A∩B)= P(B | A)·P(A)
代入:
P(A | B)= P(B | A)·P(A)/ P(B)
这是贝叶斯定理的最简单形式。
现在,假设B依赖于它之前发生的多个事件。将Total Probability Rule应用于上面的表达式,我们得到
P(Ai | B)= P(B | Ai)·P(Ai)/(P(A1)·P(B | A1)+ ...... + P(An)·P(B | An))
这是我们通常在各种实际应用中使用的贝叶斯定理的形式。
贝叶斯定理的应用由于其预测性,我们使用贝叶斯定理推导出朴素贝叶斯,这是一种流行的机器学习分类器
如上所述,贝叶斯定理基于可能与事件相关的因素的先验知识来定义事件的概率。现在,基本上对于数据点xi,我们必须预测当前输出Y所属的类。假设输出的总类数为'j'。然后, P(y = c1 | x = xi) - - >告诉我们,对于给定的输入xi,y是c1的概率是多少。 P(y = c2 | x = xi) - - >告诉我们,对于给定的输入xi,y是c2的概率是多少。
在所有这些概率计算中,y属于具有最大概率的特定类。
我们将使用贝叶斯定理进行这些概率计算。
这给出了输出属于数据点(xi)的当前值的第j类的概率。 因为对于所有类1,2,...,j,分母将具有相同的值,所以我们可以在进行比较时忽略它。因此,我们获得了计算概率的公式。
为什么它被称为朴素??
我们之所以称之为朴素,是因为我们做了一个简单的假设,即类中特定特征的存在与任何其他特征的存在无关,这意味着每个特征彼此独立。
概率P(y = cj)的估计可以直接从训练数据点的数量来计算。 假设有100个训练点和3个输出类,10个属于c1类,40个属于C2类,其余50个属于C3类。 类概率的估计值将是:
P(y = C1)= 10/100 = 0.1
P(y = C2)= 40/100 = 0.4
P(y = C3)= 50/100 = 0.5
为了对P(x = xi | y = cj)进行概率估计,朴素贝叶斯分类算法假设所有特征都是独立的。因此,我们可以通过单独乘以为所有这些特征获得的概率(假设特征是独立的)来计算这个,用于第j类的输出。
P(x = xi | y = cj)= P(x = xi(1)| y = cj)P(x = xi(2)| y = cj).... P(X = XI(N)| Y = CJ)
这里,xi(1)表示第i个数据点的第1特征的值,x = xi(n)表示第i个数据点的第n个特征的值。
在接受了朴素假设之后,我们可以很容易地计算出单个特征概率,然后通过简单地乘以结果来计算最终概率P'。
使用上面的公式,我们可以计算输出y对于给定的第i个数据点属于第j个类的概率。
这是贝叶斯定理在实际应用中的主要应用。
本文内容由小馨整理编辑!