> 动物
支持向量机svm的优缺点(支持向量机是算法吗)
导语:机器学习算法——支持向量机(SVM)
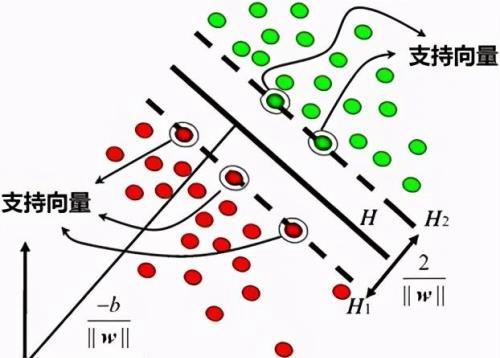
支持向量机(SVM)图解
1、简介支持向量机方法是建立在统计学习理论的VC维理论和结构风险最小原理基础上的,根据有限的样本信息在模型的复杂性(即对特定训练样本的学习精度)和学习能力(即无错误地识别任意样本的能力)之间寻求最佳折衷,以期获得最好的推广能力。
SVM的关键在于核函数。低维空间向量集通常难于划分,解决的方法是将它们映射到高维空间。但这个办法带来的困难就是计算复杂度的增加,而核函数正好巧妙地解决了这个问题。也就是说,只要选用适当的核函数,就可以得到高维空间的分类函数。在SVM理论中,采用不同的核函数将导致不同的SVM算法。
在确定了核函数之后,由于确定核函数的已知数据也存在一定的误差,考虑到推广性问题,因此引入了松弛系数以及惩罚系数两个参变量来加以校正。在确定了核函数基础上,再经过大量对比实验等将这两个系数取定,该项研究就基本完成,适合相关学科或业务内应用,且有一定能力的推广性。当然误差是绝对的,不同学科、不同专业的要求不一。
2、SVM的不足在海量数据处理中,SVM面临两个困难:
1)SVM算法对大规模训练样本难以实施
由于SVM是借助二次规划来求解支持向量,而求解二次规划将涉及m阶矩阵的计算(m为样本的个数),当m很大时该矩阵的存储和计算将耗费大量的机器内存和运算时间。
2)利用SVM解决多分类问题存在困难
由于经典的支持向量机算法只给出了二类分类的算法,而在数据挖掘的实际应用中,一般要解决多类的分类问题。其解决方法一般如下:
A、通过构造多个二类支持向量机的组合来解决。主要有一对多组合模式、一对一组合模式和SVM决策树。
B、通过构造多个分类器的组合来解决。这样不仅克服了SVM的缺点,而且结合其他算法的优势,解决了多累分类问题的精度。
本文内容由小姿整理编辑!