java中的泛型是什么使用泛型的好处(java中的泛型是什么)
导语:Java中的泛型是什么?
什么是泛型
在java代码中经常见到类似class<S,T>这样的写法,例如在阅读JDK中Map和List接口时发现接口定义如下:
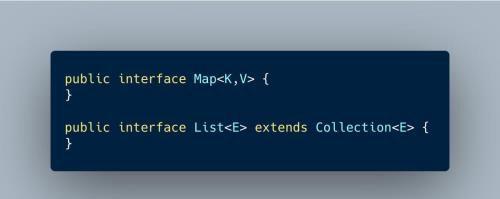
Map和List接口定义
Map中的K,V和List中的E分别代表什么意思呢?这是JDK1.5中引入的特性--泛型。
泛型实现了类型参数化,也就是说在编写代码的时候可以不考虑传入的类型,在创建参数化类型的实例时,编译器会负责转型操作,并保证类型的正确性。例如JDK在定义List接口时候不用考虑List中将来要放什么类型的对象,在程序员写代码定义List对象时需要指出List中存放的类型,如果不指定,则默认为Object。
需要说明的是,泛型仅仅在编译时存在,也就是说JVM其实并不会识别泛型,在编译期间所有的泛型信息会被擦除掉,称为类型擦除。编译器会将泛型类型替换为实例化时指定的类型,或者推断出来的类型。
为什么要用泛型
使用泛型的原因是为了使代码更加灵活,比如说实现一个List为了能够存放任何类型的对象,其它容器类也类似。但是还是有一个疑问,如果为了满足List可以存放任何类型的对象,List内部可以使用Object就可以了,因为所有类都是直接或者间接继承自Object。这样真的可行吗?
先看一下如下代码:

非泛型demo
这个代码在编译时期时不报错的,但是在执行时会报错吗?答案是肯定的。会报java.lang.ClassCastException: java.lang.Integer cannot be cast to java.lang.String异常。
这就是为什么不能使用Object的原因,类型转换是不安全的,这个错误在编译时是不会发现的,只有当运行时才暴露出来。
改成泛型实现如下:
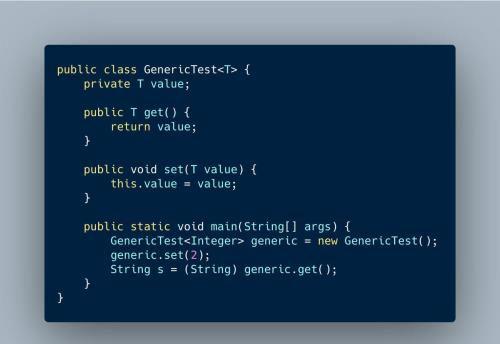
泛型demo
这样在代码最后一行尝试将generic.get()转换为String类型时编译器就会提示报错。避免运行时才发现错误。
因此,使用泛型主要由以下几点好处:
提高代码重用性,例如List中可以存放各种类型的对象。在编译时提供更加强大的类型转换。就像上面的例子。消除显式转换。不需要显式的做类型转换,因为类型在对象实例化的时候已经确定或者在泛型方法中编译器可以推断出类型。泛型接口和类
泛型类和接口上面已经演示过了,定义方式类似class A <S,T>这样。需要注意一点,在实现泛型接口时可以选择传入泛型实参或者不传实参,传入实参时实现类不需要声明为泛型,实现类中所有使用泛型的地方都要转为实参。不传入实参时,实现类也要声明为泛型。
泛型方法
泛型方法能够使方法独立与类而产生变化,Java编程思想一书中有一个指导原则,无论何时,只要能做到,就应该尽量使用泛型方法。也就是说,如果使用泛型方法可以取代将整个类泛型化,那么就应该只使用泛型方法。另外,对于一个static的方法而言,无法访问泛型类的类型参数,所以,如果static方法需要使用泛型能力,就必须使其成为泛型方法。
看一个简单例子:
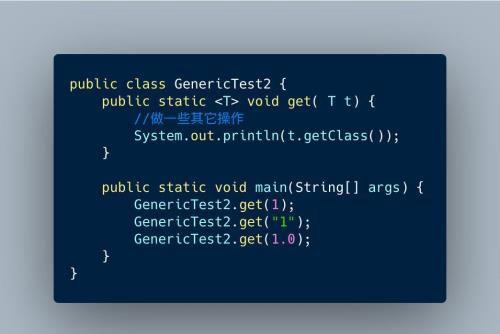
泛型方法
首先上面这个类是普通类,并不是一个泛型类。这个类有一个泛型方法,这个方法可以静态的也可以是静态的,我这里选择用静态方法。方法get很简单,就是打印出参数的类型。在定义方法的时候,并不知道要传入的方法类型,只有在编译时期根据传入的参数类型,可以推断出泛型的实参,例如传入的1,编译器可以推断出泛型参数类型为Integer,传入“1”,编译器可以推断出泛型参数类型为String,传入1.0编译器可以推断出泛型参数类型为Double。这个叫做参数类型推断。
看下上面代码执行结果:
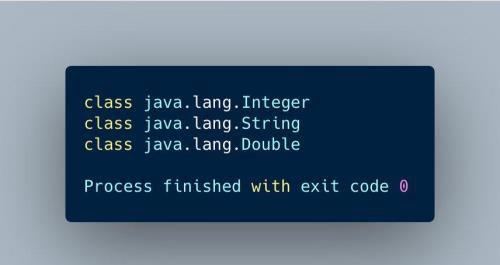
执行结果
代码的执行结果证明了泛型方法不需要显式的指明参数类型,可以推断参数类型。类型推断只对赋值操作有效,其他时候并不起作用。如果你将一个泛型方法调用的结果(例如New.map())作为参数,传递给另一个方法,这时编译器并不会执行类型推断。
综上所述,当使用泛型类时候,必须在创建对象的时候指定类型的参数值,而使用泛型方法的时候,通常不必指明参数类型,因为编译器会找出具体的类型。
通配符
在定义泛型过程中会经常遇到不同的通配符,例如 T,E,K,V ,?等,这些其实没什么区别,但是默认情况下有一些约定:
T表示一个java类型。
E表示元素Element,表示容器中的元素。
K V (key Value) 分别代表java键值中的Key Value。
?表示不确定的java类型。
通配符一般可以分为无界通配符,上界通配符和下界通配符。
定义方式如下:
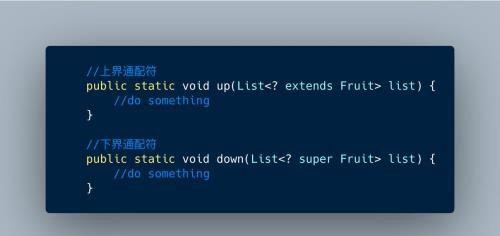
上界和下界通配符
但是上界通配符和下届通配符是具有局限性的。在上图的list中,上界通配符定义的list只能get数据,且类型为Fruit,add的时候会报错。下界通配符定义的list只能add数据,get数据返回的只能是object,详细信息会全部丢失。
我个人认为主要原因是上界通配符定义了上限Fruit,但是没有定义下限,可能是Fruit的子类或者子类的子类等等,编译器无法确定到底是哪个类,为了防止类型转换错误,就禁止add,get时获取的类型应该为Fruit类型,因为子类可以安全的转换为父类。下界通配符定义了下界是Fruit,但是没有定义上界,编译器认为上界是Object,所以返回的是Object,但是类型的详细信息会丢失,add的对象都是fruit的父类或者父类的父类,相当于放松了对元素的类型控制,因此add是没问题的。
免责声明:本站部份内容由优秀作者和原创用户编辑投稿,本站仅提供存储服务,不拥有所有权,不承担法律责任。若涉嫌侵权/违法的,请与我联系,一经查实立刻删除内容。本文内容由快快网络小里创作整理编辑!