自然语言的预训练模型概念简介怎么写(自然语言处理中预训练语言模型的优势包括)
导语:自然语言的预训练模型概念简介
随着深度学习的发展,各类神经网络模型开始被广泛用于解决自然语言处理(Natural Language Processing,NLP)任务,比如卷积神经网络(Con-volutional Neural Networks,CNN)、循环神经网络(Recurrent Neural Network,RNN)、图神经网络(Graph Neural Networks,GNN)和注意力机制(Attention Mechanism)等。在传统的非神经网络NLP模型中,模型性能通常过于依赖手工设计或选择文本特征,因此训练一个高性能的NLP模型通常开发周期较长。而神经网络模型的优势是可以大幅缓解特征工程问题,通过使用在特定NLP任务中学习的低维稠密向量(分布式表示)隐式地表示文本的句法和语义特征。因此,神经网络方法简化了开发各类NLP系统的难度。
尽管神经网络模型在NLP任务中已取得较好的效果,但其相对于非神经网络模型的优势并没有像在计算机视觉领域中那么明显。该现象的主要原因可归结于当前NLP任务的数据集相对较小(除机器翻译任务)。深度神经网络模型通常包含大量参数,因此在较小规模的训练集中易过拟合,且泛化性较差。通过海量无标注语料来预训练神经网络模型可以学习到有益于下游NLP任务的通用语言表示,并可避免从零训练新模型。预训练模型一直被视为一种训练深度神经网络模型的高效策略。
预训练的重要性
随着深度学习的发展,模型参数显著增长,从而需要越来越大的数据集用于充分训练模型参数并预防过拟合。然而,因大部分NLP任务的标注成本极为高昂,尤其是句法和语义相关任务,构建大规模标注数据集尤为困难。相比较而言,大规模无标注数据集相对易于构建。为更好地利用海量无标签文本数据,我们可以首先从这些数据中学到较好的文本表示,然后再将其用于其他任务。许多研究已表明,在大规模无标注语料中训练的预训练语言模型得到的表示可以使许多NLP任务获得显著的性能提升。预训练的优势可总结为以下几点:
1. 在海量文本中通过预训练可以学习到一种通用语言表示,并有助于完成下游任务。
2. 预训练可提供更好的模型初始化,从而具有更好的泛化性并在下游任务上更快收敛。
3. 预训练可被看作是在小数据集上避免过拟合的一种正则化方法。
预训练模型的任务
预训练任务对于学习语言的通用表示至关重要。本节将预训练任务分为三类:监督学习、无监督学习及自监督学习。
1. 监督学习(Supervised Learning,SL)通过学习一个函数,根据输入-输出对组成的训练数据将输入映射至输出。
2. 无监督学习(Unsupervised Learning,UL)从无标记数据中寻找一些内在知识,如簇、密度、潜在表示等。
3. 自监督学习(Self-supervised Learning,SSL)介于监督学习和无监督学习之间,其学习范式与监督学习相同,而训练数据标签自动生成。自监督学习的关键思想是通过输入的一部分信息来预测其他部分信息。例如,掩码语言模型(Masked Language Model,MLM)是一种自我监督的任务,就是将句子中的某些词删掉,并通过剩下的其他词来预测这些被删掉的词。
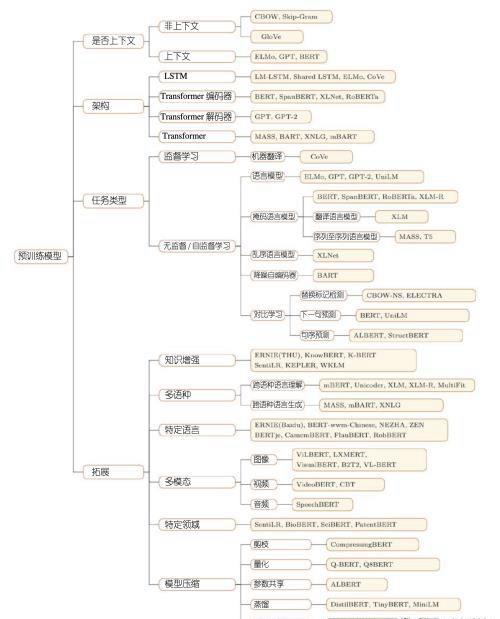
预训练模型的分类
预训练模型分类通常从四个不同角度划分其代表性预训练模型:
1. 表示类型:根据用于下游任务的表示,可将预训练模型分为非上下文预训练模型和上下文预训练模型。
2. 架构:预训练模型使用的骨干网络,包括LSTM、Transformer编码器、Transformer解码器和完整的Transformer架构。
3. 预训练任务类型:预训练模型时使用的预训练任务类型。
4. 拓展:为各种场景设计的预训练模型,包括知识增强预训练模型、多语言或特定语言的预训练模型、多模态预训练模型、特定领域的预训练模型和预训练模型的压缩等。
预训练模型分类与典型算法名称
本文内容由小面整理编辑!