自旋锁如何实现(自旋锁的底层实现原理)
导语:带您进入内核开发的大门 | 自旋锁的使用
自旋锁应该是Linux内核中使用最多的锁了,其它锁很多都依赖自旋锁实现。我们今天先介绍自旋锁,后续在介绍Linux内核的其它互斥机制。从字面意义上我们可以看出,自旋锁处于自旋的状态,什么是自旋状态呢?就是原地打转,不停的循环。下面几点是自旋锁的特点:
自旋锁(spin lock)是一种死等的锁机制。在操作系统中,为了防止资源被两个线程同时访问,导致数据不一致,通常需要一种锁机制。通常有有两种实现方式:一个是死等,另外一个是挂起当前进程,调度其他进程执行。而自旋锁则是一种死等的机制,当前的执行thread会不断的重新尝试直到获取锁进入临界区。只允许一个thread进入。信号量(semaphore)可以允许多个thread同时进入,而自旋锁一次只能有一个thread获取锁并进入临界区,其他的thread都是在门口不断的尝试。执行时间短。由于自旋锁死等这种特性,因此它使用在那些代码不是非常复杂的临界区(也就是切换线程成本相对于临界区的访问成本很高的场景)。如果临界区执行时间太长,那么不断在临界区门口“死等”的那些thread将会耗费大量的计算资源,显然是不合适的。可以在中断上下文执行。由于不睡眠,因此自旋锁可以在中断上下文中适用。基本接口介绍
了解了自旋锁的基本特征,接下来我们介绍一下自旋锁的常用接口。对于基本的使用,自旋锁的使用很简单,主要涉及3部分内容:
定义一个自旋锁对临界区加锁使用完后解锁定义一个自旋锁
定义自旋锁就好像定义一个变量。下面函数用于定义一个自旋锁。

自旋锁加锁
自旋锁加锁就是组织其它线程对相同临界区的访问,使用方法也非常简单。函数原型如下:

自旋锁解锁
不多废话了,下面是函数原型:

试探加锁
由于自旋锁在临界区已经加锁的情况下会导致其它想进入临界区的线程处于忙等状态,这样会消耗CPU资源。有的时候我们不想这样,内核又提供了另外一个接口,该接口会首先判断是否可以进入,如果可以进入则获取锁资源,否则返回失败。

应用示例
我们这里只是一个非常简单的示例,在该示例中有2个线程,分别进行对同一个变量的运算。如果没有保护机制,数据将被计算混乱。通过自旋锁,使得计算可以依次有序的进行,从而保证数据的正确性。
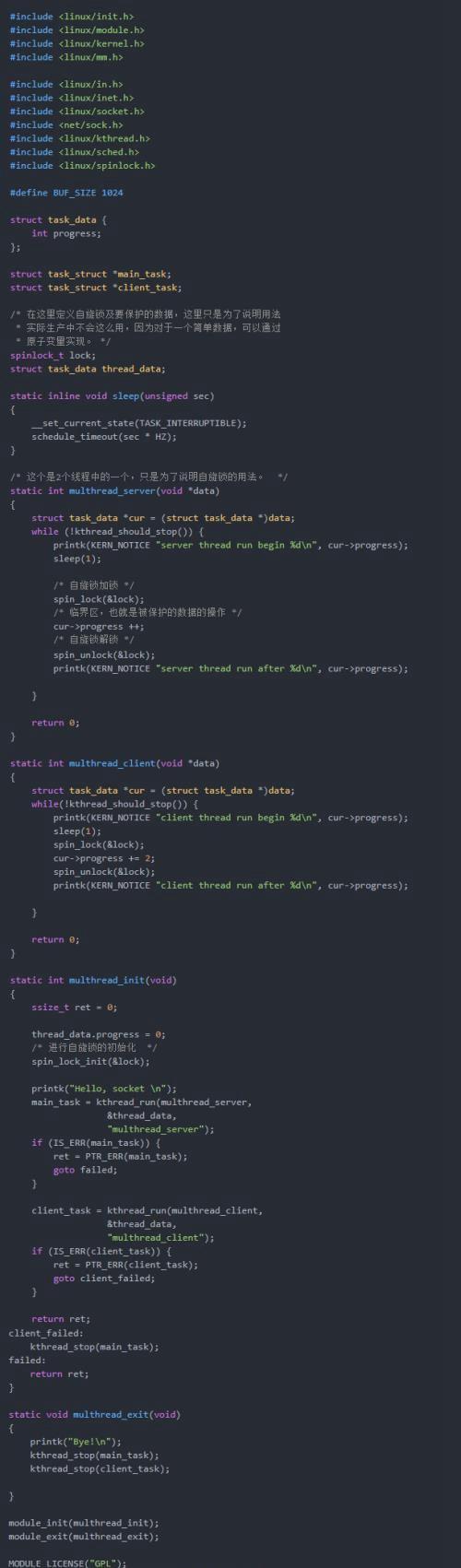
自旋锁的实现
自旋锁的基本原理和使用是比较简单的,下面我们分析一下自旋锁的实现。任何机制的出现肯定是为了解决某些问题,我们先看一下自旋锁是为了解决什么问题。
大家都知道,在CPU和内存之间包含一级缓存、二级缓存和三级缓存等缓存。原因很简单,因为CPU访问缓存的速度更快,将将经常访问的数据加载到缓存中,可以减少内存访问的频率,从而提高计算的性能。CPU、缓存和内存的关系如下图所示(简图,省略了好多内容):
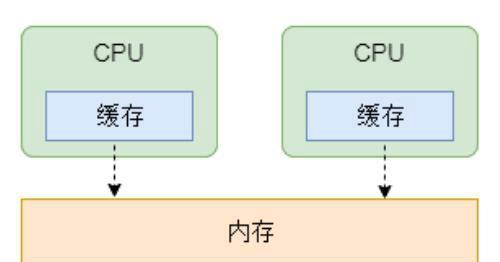
计算机缓存机制
那么缓存跟我们的自旋锁又有什么关系呢?有了缓存之后,就可能出现缓存中数据和内存中数据不一致的情况。一方面是CPU无法直接更改内存中的值,更改操作需要至少读和写两条指令,从而导致改写操作的非原子性;另一方面是因为缓存是为了提升性能,因此CPU更新了缓存内容后原则上不会马上更新到内存,否则就失去了缓存的意义。
如2所示,在没有任何保护机制的情况下,假设在内存中有一个变量val本来值为2,两个处理器同时对该值进行操作,左边CPU从内存读取该值,并进行+1运算后该值为3。而在右侧CPU从内存读取数据,并进行+2运算后结果为4。这样,两个CPU更新到内存的时机不同,则内存中的结果就会不同,也就是程序每次运行产生的结果可能是不一样的。问题的关键是CPU同时对内存中的数据进行了读和运算操作,而该操作本身不具备原子性,也就是分为读和写两步,这样导致结果非预期。这种情况显然我们是不能接受的,这种情况下就需要自旋锁出马了。自旋锁的目的就是将对同一个数据的并行运算串行化,也就是你改完后我再改,从而保证结果的一致性。
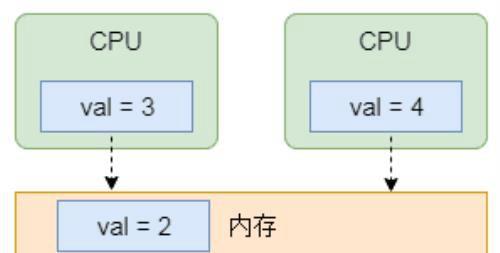
缓存数据不一致
老版本的实现解析
为了容易理解,我们先看一下老版本(2.6.0)的Linux内核的自旋锁是如何实现的。我们从自旋锁的数据结构开始,对于X86体系结构具体定义如下。
typedef struct { volatile unsigned int lock;endif} spinlock_t;忽略掉调试功能的代码,其实就变的很简单了,也就是只有一个volatile unsigned int 的变量。volatile关键字表示该变量的改变马上更新到内存,不进行缓存。
在介绍之前我们可以猜测一下,通过这个变量进行标识自旋锁是否已经加锁,如果为1则表示已经加锁,为0则表示没有加锁。在没有加锁的情况下,线程可以获得该锁,然后将变量置为1。其它线程由于发现该值为1,所以只能等待。而当线程解锁的时候,将该变量设置为0,此时其它变量就可以进行加锁了。或者将加锁和未加锁的标示反过来,也就是0表示加锁,1表示未加锁。这个都无所谓,只是一种状态标识。
实际上Linux内核的实现就是上面我们描述的样子。我们通过自旋锁的几个函数分别看一下其具体实现。
自旋锁初始化
下面代码是锁的初始化代码(初始化为1),可以看出其实就是将结构体的变量初始化为1。

自旋锁加锁
接下来我们看一下自旋锁加锁的具体实现。外面的do-while是Linux内核宏定义的惯用手法,这里知道就可以了。可以看到这里一共调用了3个函数,具体每个函数的作用在代码中介绍。

下面代码是试图加锁函数(_raw_spin_trylock)的代码。这里面是通过内嵌汇编的方式实现的。这段汇编的大概含义是对lock->lock与0值进行交换,并将lock->lock存储到oldval中,如果oldval为正值,就返回1,
否则返回0。这里面lock->lock就是存储锁数据的变量,前面我们介绍过,其初始值(未加锁状态)为1。因此,如果该锁处于为加锁状态时,交换后oldval中的值为1,此时会加锁成功,函数的返回值为真。如果lock->lock中的值为0,交换后oldval中的值为0,那此时加锁就失败,函数的返回值为假。
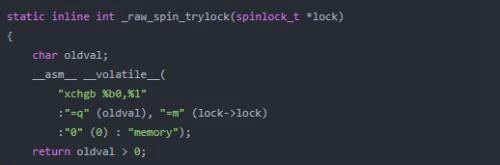
加锁失败的情况下,spin_lock函数会进入__preempt_spin_lock函数的逻辑。粗看代码,这里又有一个do-while循环,这个循环其实就是自旋锁自旋的地方。可以看到while里面试图对锁进行加锁操作,如果加锁成功会退出循环,而如果失败则继续循环。
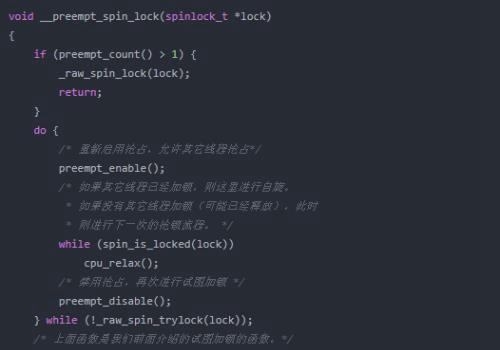
总结一下,自旋锁的实现其实就是通过原子汇编语言实现了对自旋锁变量的赋值操作,并且在无法加锁的情况下自旋等待。
自旋锁解锁
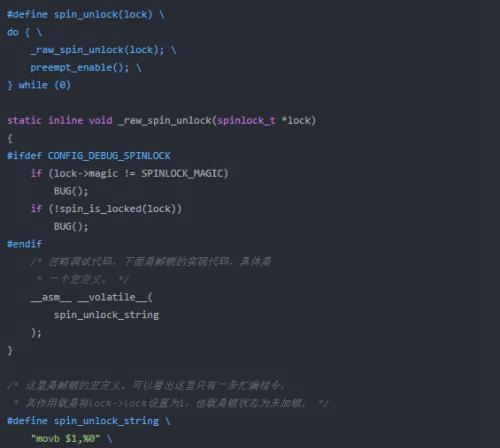
自旋锁解锁的流程要稍微简单一些。下面将相关的几部分代码放到一起了。具体调用过程是spin_unlock->_raw_spin_unlock->spin_unlock_string。解锁完成后需要开启抢占。
新版本的实现解析
有可能存在多个线程同时争抢自旋锁的情况,但老版本的实现无法保证前抢的一定能得到自旋锁。因此新版本(2.6.25以后)的实现排队功能,也就是先到先得。我们照例先从自旋锁的数据结构开始,对于X86体系结构具体定义如下(这里是最终定义,前面的嵌套调用关系这里没有介绍,大家自行看一下)。这里__ticketpair_t和__ticket_t就是无符号整型数,大家可以自行看一下代码。
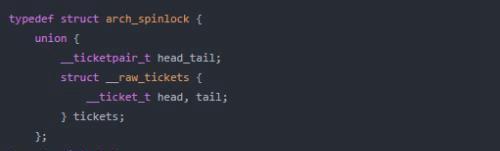
这里实际上还可以理解为一个整数两部分(或者两个整数)。有些人可能会好奇,通过整数就可以实现排队自旋锁了?是的,就是这么简单,当然还需要一些算法,程序本身就是数据结构和算法的集合嘛!先看一下这个结构体是怎么用的。
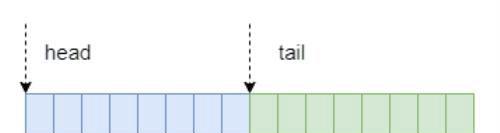
自旋锁数据结构示意图
其实排队自旋锁的原理很简单,就是判断head和tail两个变量的值,如果相等则为未加锁,否则说明已经处于加锁状态。自旋锁初始化将head和tail都设置为0。当有线程加锁的时候,首先判断head和tail是否相等,相等就将tail加1,此时加锁成功。如果两者不相等则表示已经有其它线程加锁,此时只能等待。
自旋锁加锁
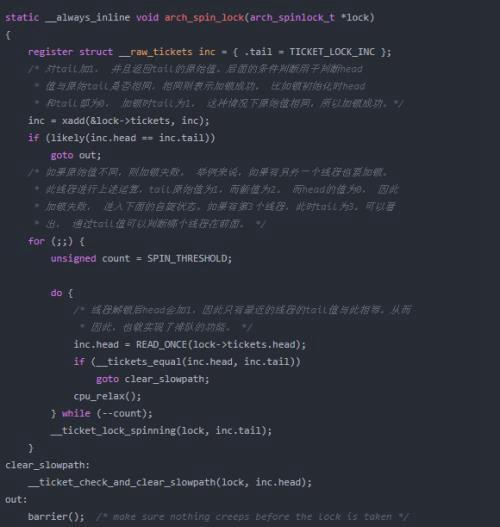
这里面使用了一个名为cmpxchg的函数,该函数完成的功能是:将old和ptr指向的内容比较,如果相等,则将new写入到ptr中,返回old,如果不相等,则返回ptr指向的内容。这里请自行阅读代码,本文就不贴代码了。
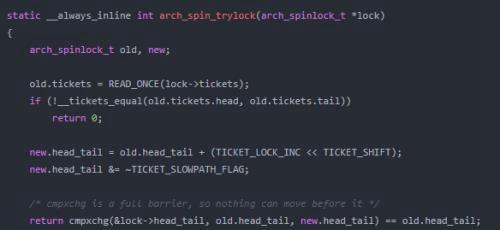
尝试加锁实现
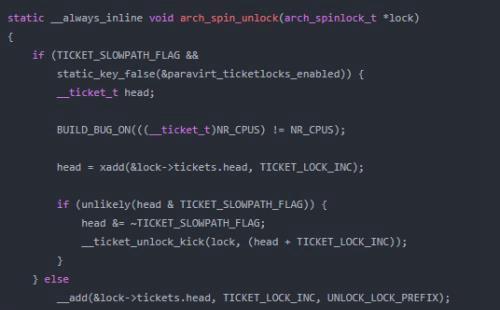
自旋锁解锁实现
自旋锁解锁实现要简单的多,下面是X86的实现。仅仅是将head进行加1操作。需要注意的是必须保证该操作的原子性。这里就不多废话了。
能力增强
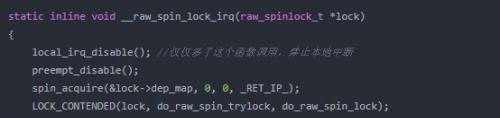
除了上面介绍的基本的加锁和解锁的接口外,Linux内核还实现增强的功能。比如可以在中断环境中使用的自旋锁和下半部使用的自旋锁等等。下面是自旋锁所涉及的接口列表。

我们以支持中断的自旋锁为例进行说明。其实支持中断的自旋锁内部仅仅增加了禁止本地中断的函数调用。具体为什么加这个,大家可以自行思考一下,原因是比较清楚的,本文不再赘述。
关于自旋锁的内容还很多,比如读写自旋锁,单核自旋锁的特殊处理等等。由于篇幅问题,本文不再赘述。后续我们在另起文章进行阐述。
免责声明:本站部份内容由优秀作者和原创用户编辑投稿,本站仅提供存储服务,不拥有所有权,不承担法律责任。若涉嫌侵权/违法的,请与我联系,一经查实立刻删除内容。本文内容由快快网络小心创作整理编辑!