神经网络的原理和bp算法的区别(神经网络bp算法应用)
导语:神经网络的原理和BP算法
神经网络的原理和BP算法
神经网络,中间我们假设有一个合适的 θ 矩阵,来完成我们的前向传播,
那么我们如何来选择 θ 呢?
开始我们的讨论内容,构造一个神经网络,使用反向传播求解 θ 。
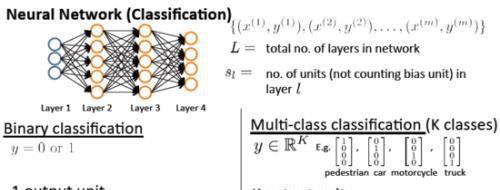
神经网络模型:
说明:
L :神经网络层数
Sl:第 l 层神经元个数
K :输出的多分类情况中的分类数
这时候,要求一个好的神经网络就要对所有的边权 θ 进行优化,这时候我们想到的是损失函数和梯度 下降。
代价函数:
图中,我们看出神经网络的代价函数是逻辑回归代价函数的一种普遍化表达,我们可以理解为有多个 逻辑回归单元。所以,如果是二分类问题代价函数是逻辑回归的代价函数形式,如果是多分类,就需 要把每个分类的代价都算进总代价。同样,式子二中的正则化项是把每一层的所有神经元所有边权?θ 都加起来(除了偏置项)。
代价函数也可以用 SVM / hinge loss 和 Softmax / Cross-entropy loss 。
所以神经网络的代价函数中同样是前一个式子表示模型拟合能力,后一项表达神经网络复杂度。
有了代价函数,下一步就是求最合适的边权?θ 使得代价函数最小化。如何做呢?
BP算法(反向传播)
我们的目标:
整体思路,用反向传播求每一个边权 θ 的梯度,也就是导数,用梯度下降法求边权 θ 最优解。
上图一中,通过前向传播我们可以计算得到输出结果和中间结果对应的向量。
这时候,我们用 δ 下标 j上标l,表示第1层的第 j 个节点的误差。也就是激活值和真实值的误差。
讲一下反向传播:
前面的博客中,我们把 a 上标l,下标 j 表示的是第l层第 j 个单元的激活值,也就是神经元的输出值。所以,δ 项在 某种程度上就捕捉到了我们在这个神经节点的激活值的误差。
具体地说,我们上图中这个有四层的神经网络结构为例,那么大写 L 等于 4,对于每一个输出单元,准备计算损失的 δ项。第四层的第 j 个单元的 δ 就等于这个单元的激活值减去训练样本里的真实值,就是假设输出和训练集y值之间的 差。
下一步,计算网络中前面几层的误差项 δ。
δ(4):输出层的输出结果减去样本值。
δ(3)的公式: δ(3)等于θ(3)的转置乘以δ(4),然后点乘g’(z(3))。
g’(z(3)):激活函数 g 在输入值为 z(3) 的时候所求的导数。g’ 这个导数项,其实是 a(3) 点乘 (1-a(3)),这里a(3)是第三 层的激活向量。
同样的公式计算δ(2)。
没有δ(1),因为它对应输入层,是训练集数据,没有误差,所以这个例子中,我们的δ项就只有第2层和第3层。
反向传播就是类似于我们把输出层的误差,反向传播给了第三层,然后再传到第二层,这就是反向传播的意思。
下一步,介绍了BP算法的思路后就是用这个方法计算参数 θ 的偏导数。
当我们有一个非常大的训练样本集时,如上图,假设我们有m个样本的训练集。
第一件事就是固定这些带下标 ij 的 Δ(就是 δ 的合集),这其实是大写的希腊字母 δ 。我们将他们统一设置成 0。实际 上,这些大写Δij会被用来计算偏导数项,也就是 jΘ 上标,下标 ij的偏导数。
所以,如上图中,这些 Δ 会被作为累加项(初始值 0),慢慢地增加以计算出这些偏导数。
我们遍历我们的训练集,写成 for i = 1 to m,对于第 i 个循环而言,我们将取训练样本 (xi, yi) 。
首先,我们设定 a(1) 也就是输入层的激活值。设定它等于 xi,xi 是我们第 i 个训练样本的特征向量,接下来我们运用正 向传播来计算第二层的激活值,然后是第三层、第四层。一直到最后一层L层。
接下来,我们将用我们这个样本的输出值 yi?来计算这个输出值所对应的误差项δL,所以δL就是假设输出减去目标输出。
接下来,我们用反向传播算法来计算δ(L-1), δ(L-2),一直这样直到δ(2) 。
最后,我们用大写的 Δ 来累计我们在前面写好的偏导数项。具体地说,如果我们把 Δ 看作一个矩阵,ij 代表矩阵中的 位置。那么如果 Δ(L) 是一个矩阵,我们就可以写成 Δ(l) 等于 Δ(l) 加上小写的 δ(l+1) 乘以 a(l) 的转置,用向量化的形式 实现了对所有 i 和 j 的自动更新值。最后,执行这个for循环体之后,我们跳出这个for循环,然后计算上图三中左下角这些 式子,计算 D 。我们对于 j=0 和 j≠0 分两种情况讨论。
在 j=0 的情况下,对应偏差项,所以当 j=0 的时候,这就是为什么我们没有写额外的标准化项。
最后,计算出来了这些,这就正好是代价函数对每一个参数的偏导数(梯度),所以我们可以把它们用在梯度下降法或者 其他一些更高级的优化算法上以寻求适当的参数或者边权来最小化整体代价。
这时候,有点云里雾里,到底怎么计算 Δij?
首先来回顾一下神经网络的代价函数。假设只有一个输出单元时候的代价函数。
我们关注单个样本的前向后向传播,比如我们这里考虑样本 (xi, yi) 。同时我们现在不考虑正则化,所以λ=0 。所以最后一 项去掉。现在再来看这个求和公式,你会发现,这个代价项和我们的训练数据xi, yi相关。所以,单个样本的代价仅仅就是上 图左下角蓝色框的 cost 。简单来说,我们的目标是平均意义上使得这个值最小,它的值衡量了模型对真实数据的拟合能力, 那么我们要做的就是尽可能地降低这个cost 。
反向传播细节和Δij 计算:
我们将 δ(l) j 看成第l层第 j 个单元激活值的代价。更加正式地说,δ 项实际上是关于z(l) j的偏微分。
记得δ(3)的公式:
δ(3)等于θ(3)的转置乘以δ(4),然后点乘g’(z(3))。吗?
所以,代价函数是关于标注 y 以及整个网络表达的假设函数 hΘ(x) 之间的一个函数。那么如果我们在神经网络内部,对z(l)j 的值做了一点点修改,那么它会对整个网络的输出造成一些影响,而这会进一步影响代价函数。所以,这些δ项其实就是代 价函数关于这些内部中间项的偏导数而已。
它们能够度量我们修改神经网络内部权重的时候对整个代价函数会产生怎样的影响。
现在我们来仔细看看,反向传播究竟是怎么做的。
对于输出层,我们的 δ(4)1,它等于y(i)-a(4)1。 所以这是真实的误差。它是真实值和神经网络预测出来的值之间的差。
下一步,我们将把这个值反向传播,然后不断向前传播以计算每一个隐层节点的δ。
其实整个反向传播做的事情就是在做求导的链式法则而已。
链式法则我们非常简单地提一下:
实际上,我们的神经网络定义了一个非常复杂的假设函数 hΘ(x),我们上图里面的 z 和 a 实际上也都是函数,而且它们都 是嵌套在 hΘ(x) 中的。因此,对于这个大的嵌套函数,在需要对某个参数 Θ(l)ij 求偏导的话,其实就是在不断地在整个反 向链路上求所有的嵌套它的函数的偏导。最终,它就是我们这里写出来的这样的规则 δ(2)2 和 δ(3)2 公式。
梯度检验
验证我们反向传播的正确与否。
随机初始化
首先思考一个问题,如果我们把所有边权初始化为 0 会怎么样? 我们计算的激活值很可能相同,类似于我们只有一个特征做逻辑回归,效果很差。 这时候我们需要随机初始化参数来解决这个问题。
具体来说,上面我们讨论的问题叫做对称现象,所以随机初始化这种技术有时候也被称为打破对称。
随机初始化,我们可以指定初始化在一定的范围内,比如 [-ε,ε],这样我们的所有参数都随机的被初始化,且在一定 的范围内。
那么我们就可以编写上面的代码来进行初始化。我们的 rand 函数会返回所被要求的维度,但重要的是,它能够返回0~1 之间的一个随机数,然后我们将它乘以2倍的ε,这样,我们就得到了0~2ε之间的一个数值,我们再减掉一个ε,这样我们 就得到[-ε,ε]之间的数值了。
我们这里面说的 ε 和梯度检验里面的 ε,以及之前提到的判断是否收敛时用的 ε 都不是一回事。它们在各自的场景用其实 均扮演了一种极小值的角色,因为在数学中极小值一般都是用 ε 这个字符,所以在这些不同的场景中均称它们是 ε 。这里 我们为了避免混淆,我们可以在代码中将它的变量名称为init_epsilon。
总结
我们在训练一个神经网络的时候,第一件事,就是搭建网络的大体框架。
网络框架的含义是,神经元之间的连接模式,如上图一。所以,网络框架的含义就是:有多少层,以及每层有多少个 节点,对于更复杂的可能层与层之间都不是全连接的。
具体怎么选择呢?
首先,我们知道,我们已经定义了输入单元的数量,一旦我们确定了特征集x,对应的输入单元数目也就确定了,也就 是等于特征xi的维度,如果正在进行多类别的分类问题,那么输出层的单元数量将会由分类问题中所需要区分的类别个 数决定,比如二分类我们只需要一个输出单元即可,但是对于一个数字识别应用而言,我们可能就有10个目标分类,而 且我们还需要把这些分类重写成向量的形式。
隐层是对初始特征的高级加工,所以隐层其实神经元数量越多越好,隐层层数也是越多越好,这样可以更好地抽象高级 特征。但是越多的隐层或者隐藏神经元,也意味着更大的计算量和更加复杂的优化算法。所以,对于一般的简单应用, 我们使用一两个隐层几乎也就够了,如果需要更多,那么很可能就已经进入深度神经网络,也就是现在很热的深度学习 的范畴了。
训练一个神经网络:
六个步骤:
1、构建一个神经网络,然后随机初始化权值,通常我们把权值初始化为很小的值,接近于0,但不是0 。
2、执行前向传播算法,也就是对于该神经网络的任意一个输入xi,计算出对应的hx值,也就是一个输出值y的向量。
3、通过代码计算出代价函数 jΘ 。
4、执行反向传播算法,来计算出这些偏导数,或者叫偏微分项,也就是 jΘ 关于参数 Θ 的偏微分。这样我们就能得到该 神经网络中每一层中每一个单元对应的所有这些激活值a(l)以及δ项。
5、梯度检验,比较使用反向传播算法计算出来的偏导数值和使用数值方法得到的估计值,以此来确保两种方法得到基本 接近的两个值。通过梯度校验,我们能够确保我们的反向传播算法,得到的结构是正确的。
6、使用一个最优化算法,比如梯度下降算法来与反向传播算法相结合,这样我们就可以尽量降低代价函数,求得合理可 用得参数Θ矩阵了。
对于神经网络代价函数 jΘ,它是一个非凸函数,因此理论上是能够停留在局部最小值得位置上的,实际上梯度下降算法和 其他一些高级优化方法理论上也都收敛于局部最小值。
最后,说一下梯度下降算法和神经网络的联系。上图四。
我们有某个代价函数,并且在我们的神经网络中,有一系列参数值,这里我们只写下了两个参数值,当然实际上,在神经 网络里,我们可以有很多的参数值 Θ(1), Θ(2) 等很多边权。所有的这些都是矩阵,因此我们参数的维度就会很高了,由于 绘图的限制,我们不能画出更高维度情况的图像,所以这里我们假设,这个神经网络中只有两个参数值。
那么,代价函数jΘ度量的就是这个神经网络对训练数据的拟合情况。
因此,梯度下降算法的原理是,我们从某个随机的初始点开始,不断沿着某一方向走到最小值。
那么反向传播算法的目的就是算出,梯度下降的方向,而梯度下降的过程就是沿着这个方向一点点的下降。
本文内容由小莉整理编辑!