hashmap是如何实现的(hashmap详细讲解)
导语:hashmap 是如何炼成的
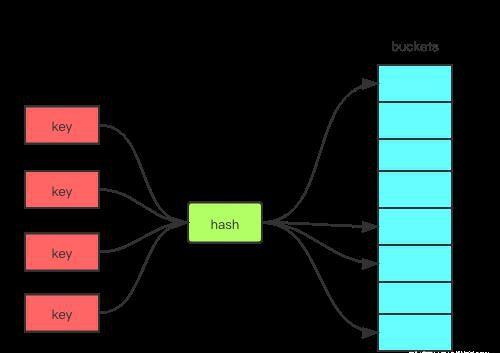
hashmap 是程序员日常使用频率比较高的数据结构之一,是一种 key-value 结构。那么它的底层原理是如何实现的呢?对于 hashmap 的实现来说,无非涉及到以下几点
hash 冲突hash 映射初始容量与扩容rehash并发安全hash 冲突所谓的 hash 冲突即是指多个 key 通过 hash 计算后得到相同的 index,那么此时就需要有策略去应对这种情况。常见的 hash 冲突解决方法有
链地址法开放地址法链地址法比较好理解,当发生冲突时,使用链表来进行存储,直接看图
当然单纯使用链表是有问题的,如果冲突太多那么就可能导致链表过长,遍历起来就比较耗时,时间复杂度为 O(n)。一般的改进方法为如果链表长度达到某个阈值后就改为用红黑树。这其实也是 JDK 1.8 HashMap 的实现方式
开放地址法,如果 key 通过 hash 计算后发现冲突,那么就向后寻找下一个空的 bucket,如下
如果向下查找的步长为 1 的话,那遍历时间就太长了,一般情况下我们会增大步长,同时对 buckets 的大小也是有要求的,必须为质数。假设 buckets 长度为 11,步长为 5,那么遍历结果为
0, 5, 10, 4, 9, 3, 8, 2, 7, 1, 6, 0, 5, 10, ...稍微比较下两者,开放地址法容易产生堆积问题,既是大量元素通过 hash 计算后堆积在 buckets 的某一处。同时插入元素时容易产生多次冲突,可以说开放地址法比较适合小数据量的场景,所以我们可以看到大多数编程语言的 hashmap 实现使用的是链地址法
hash 映射hash 映射一般采用取模法。取模法最好理解,如下
index = key % len(buckets)像初始容量应该默认设置多少合适,扩容负载因子 (load factor=size/capacity) 应该设置多少合适等等这些其实都没标准答案,我们只能见仁见智。这里我们以 Java 为例
初始容量默认为 16扩容的负载因子为 0.75,扩容比为 2,设置合理的话,可以有效的降低冲突比例缩容,有扩容自然就有缩容,但是一般不会进行缩容的,很大原因是为了避免频繁进行扩容与缩容rehash当 hashmap 的容量达到负载因子时,也就意味着需要进行扩容,那么就需要对现有的 key 重新计算一次 hash 值,这一过程称为 rehashing
一般情况下 rehash 是没有问题的,但是如果是在并发场景下,可能会出现多个线程同时进行 rehash,导致 Infinite Loop。这也就需要我们去考虑如何保证 hashmap 并发安全
并发安全要想 hashmap 并发安全,最简单的方法是加一把锁 (可以是互斥锁,也可以是读写锁),操作前加锁,操作后释放锁。这里以 go 来举例
不过这种直接对 hashmap 加锁,锁的粒度太大了,必然不是最优解。所以我们需要考虑如何去降低锁的粒度,比如我们可以采用分段加锁的方法来降低锁的粒度
可以看到需要进行两轮 hash 计算,第一轮是找到对应的 segment,第二轮是找到对应的 bucket 进行存储,这其实就是 JDK 1.7 ConcurrentHashMap 的实现方式。通过这种方式确实降低锁的粒度,但是由于进行了两轮 hash 计算,必然是会降低性能的,所以除非是并发场景,不然不推荐使用这种 hashmap
本文内容由小畅整理编辑!