> 时尚
支持向量机的基本原理是什么(支持向量机通俗易懂)
导语:浅谈支持向量机(3)
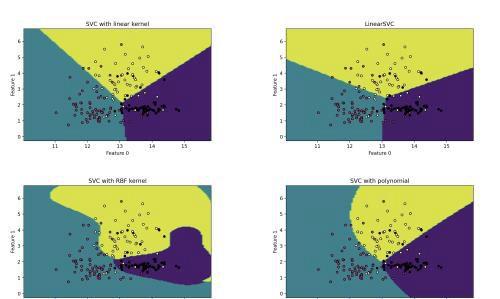
以下代码对比分析四种支持向量机分类预测的效果。使用到的支持向量机有:线性支持向量机、非线性支持向量机(线性核、高斯核、多项式核)
from sklearn.datasets import load_wine 导入支持向量机中要用的库import matplotlib.pyplot as plt 导入计算库读入红酒数据集的数据X=data.data[:,:2] 取出数据的标签值 x0,x1=X[:,0],X[:,1] 第一列特征的最小值减1和最大值加1y_min,y_max=x1.min()-1,x1.max()+1 构建两个序列,分别以x_min和y_min为起始值,差值为0.05,终值为x_max和y_max(最大只能取到max-0.05)第二步:构建分类模型models=(LinearSVC(),SVC(kernel=&34;), SVC(kernel=&39;,gamma=0.7),SVC(kernel=&39;,degree=4))使用红酒数据集来训练四个支持向量机第三步:绘图准备fig,ax=plt.subplots(2,2) 调整子图布局,wspace表示子图之间保留的宽度,hspace表示子图之间保留的高度titles=(&39;,&39;,&39;,&39;)定义函数:绘制分类的边界 z=svm.predict(np.c_[xx.ravel(),yy.ravel()]).reshape(xx.shape) 返回绘制好的分类边界,contourf函数是绘制带填充的等高线 第四步:开始绘图for model,title,ax in zip(models,titles,ax.flatten()):调用绘制分类边界函数 ax.scatter(x0,x1,c=y,cmap=plt.cm.magma,s=20,edgecolor=&39;) 39;Feature 0&39;Feature 1&设置每张子图的标题plt.show()例子使用的是sklearn自带的红酒数据集,共有178条数据,每条数据13个分类。取数据集的前两列,绘制散点图和分类边界。四个支持向量机都使用了默认的正则化系数,C=1,参数kernel指定的是非线性支持向量机使用的核,高斯核中的参数gamma表示核宽度,也就是径向作用范围。增大gamma值效果如下,过于拟合当前数据,模型复杂度高,泛化能力差。
多项式支持向量机中参数degree表示多项式的最高次幂。zip函数将对象中对应的元素打包成一个个元组,然后返回这些元组组成的列表。这里就是把模型、标题、子图序号分别打包成三个元组,model循环读取模型列表,title循环读取标题列表,ax.flatten()是把ax一维化,然后逐一取出每一个要绘制的子图。
本文内容由小畅整理编辑!