漫谈面向过程面向对象编程思维是什么(面向对象和面向过程的编程)
导语:漫谈面向过程、面向对象编程思维
万物从来不是凭空产生的?万物皆确是从无到有的。
构建电子计算机的理论基础如此,电子计算机硬件如此,编程思想如此,高级编程语言也是如此。
话说布尔提出布尔代数,香农提出在数字电路中可以实现布尔代数,冯诺依曼提出“存储程序控制”的概念。
数据和代码存储到内存,内存可寻址,控制器依次(包括跳转)读取代码,译码,产生控制信息,协调其它部件操作。
最初的程序用二进制编写,二进制使用两个符号,白茫茫的一片0和1,写、读、维护,查表(CPU抽象的指令集)都很费劲。
指令集用符号表示似乎比用0和1表示更易读、写,程序也可以用符号来写,然后再写一个汇编程序来做翻译,翻译成二进制,这就是汇编语言,相应的翻译程序叫汇编器。
更进一步抽象,叫高级语言,相应的翻译程序叫解释器或编译器。
高级语言对内存地址(一串数字,同样的不方便操作)进行命名,如变量名、常量名、函数名。
我们知道,程序的逻辑可以由减法实现,根据两数相减的结果来修改条件寄存器,通过条件和无条件跳转来实现选择和循环。
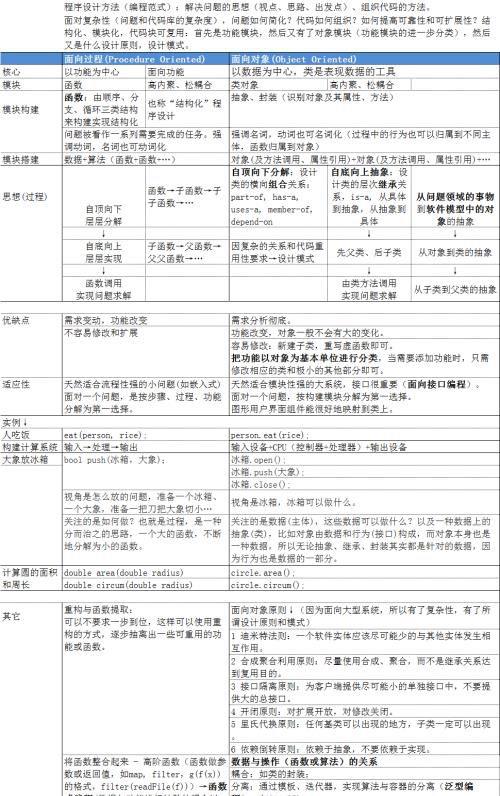
后来程序员发现,这样的跳转很容易形成无序结构,造成逻辑混乱。后来计算机科学家提出并用数学证明了用三种控制结构可以实现程序所需要的全部算法。这三种控制结构称为顺序、选择、循环结构,都只有一个入口和一个出口。三种控制结构构造函数,函数构造程序,这就是传统的面向过程,或称为结构化程序设计。
算法algorithm, 当我们编写的程序不是针对某个特殊的问题,而是针对一类问题时,我们事实上编写的是一个算法。算法是一套规则所形成的机械性过程。通过一个机械式过程来解决一类问题的一套指令规则;
对于小问题,小工具,几十个函数能够解决问题。如果碰到大问题,大一点的系统或工具软件,如浏览器,可能需要几千个函数。就会碰到函数如何组织,如何分类的问题。C语言的做法是用文件来实现模板化。头文件提供接口,源文件提供实现,使用分享编译机制。
函数处理的数据除了局部数据以外,函数之间共享全局数据,或通过函数参数来共同定义一类结构体数据的操作集(如深度优先遍历和广度优先遍历所需要的栈和队列)。通过函数和文件来组织代码,实现模块化,但当代码规模较大时,这种函数和数据的组织方式还是无法满足代码维护和扩展的需要。
面向过程的开发使得程序依赖于低层的实现细节。一旦低层的细节发生改变,上层的程序就要随之改变。在一个设计不合理的程序中,这种细节的改变甚至会导致整个软件项目的失败。因此,采用面向过程方法开发的程序,难以控制其维护成本。
面向过程还有一个难以克服的困难-缺少封装性。这表现在两个方面,一个是无法封装数据,另外一个是无法封装函数。
当一组数据需要几个函数联合起来进行处理时,要么采用全局变量,要么将数据作为参数。(如封装一个链表、或封装一个栈结构、队列结构。)
全局变量的缺点是显而易见的,即无法控制访问数据的行为。任何函数都有可能修改全局变量,甚至是不相关的函数。如果将数据当做函数参数,则会导致函数的参数列表过于复杂,同时也会因参数传递降低效率。
几千个函数如何分类?一种新的思维就是面向对象编程思想。将内聚性较强的一类函数和数据组织到(封装)到一起,通过继承和组合实现代码复用,通过多态实现代码扩展。
Niklaus Wirth在它的著作中提出Algorithms + Data Structures = Programs,没错,Algorithms在前,表示优先考虑,面对一个问题,先想处理方法、步骤或流程(procedure),然后是数据的表示与存储,这就是典型的结构化编程思想。与此相反,截然不同的编程思想是以数据结构为优先考量因素的面向过程,类的对象以数据为核心,成员函数是为数据服务的,一个类似的公式是,面向对象(接口)编程=对象+消息响应函数。
当然,编程设计的算法与数据结构,两者相互交替和相互影响的。面向对象与面向过程编程思维也是如此,两者相互补充,共生共存。
同时,面向对象与面向过程与任何事物一样,优劣同存。继承是面向对象的核心,但也由此容易产生代码臃肿和耦合的问题,多态同样如此(C++ STL就没有使用多态,而是使用了让算法通用于作为数据结构的容器的泛型编程思维)。对象的成员数据表示对象的状态,状态的不确定性有时也是一个问题,这也是函数式编程语言存在的理由。
大事化小,小事化了是一种解决问题的重要思维,同样的思维应用于算法称为分治,应用于程序设计称为分解。面向过程是“自顶向下,逐步求精”,就是描述问题过程的函数层层分解,细化,实现大函数由几个小函数去实现,逐步实现小函数,便实现了大函数。与面向过程不同,面向对象的分治思维是“自顶向下分解,自底向上抽象”,形成对象的层次上的继承关系、组合关系,以及由此衍生的设计模式。
自由总是由代价的, 不同的编程思维也是不同层面的约束:
在面向过程的语言中,函数的使用是没有限制的。而在实际开发中,一个函数的目标数据是固定的。如果不限制函数的作用范围,函数与数据之间就不会有清晰的逻辑关系,从而导致程序的可读性降低。
如果能够将函数与目标数据绑定在一起,并限制外界的访问,则可以在一定程度上克服面向过程的缺点。一方面,在形式上容易表达数据与函数间的逻辑关系,另一方面,从语言层面上减少了非法访问的机会。(将一簇数据和函数限定在类作用域内。)
面向对象的开发克服了面向过程开发的一些缺陷,将函数与目标数据绑定在一起, 具备了封装性, 使得对象的行为(函数)与属性(数据)之间的逻辑关系清晰, 程序的可读性强, 并且从语言层面上减少了非法访问的机会。对象的属性封装在对象的内部,外界无法得知。外界通过接口调用对象的行为, 这就使得在程序开发及以后的维护中, 只要这个接口不变, 无论其内部实现如何改变都不会影响使用者的调用, 这在很大程度上降低了软件的维护成本。另外,类的继承和多态等特征也有利于软件的功能扩展、代码的重用和维护,以及提高软件开发效率。(提高了数据处理的颗粒度)
-End-
本文内容由小樊整理编辑!