什么是数据库(数据仓库的概念及用途)
导语:数据仓库的概念
什么是数据仓库?
数据仓库是一个面向主题的、集成的、稳定的、反映历史变化的数据集合。
数据仓库用来做什么呢?
数据仓库用来支撑企业经营决策。
举一个例子,如果要分析公司一年中每个季度的销售额,要分析每年季度的同比增长情况,就需要用到数据仓库。
面向主题,是指数仓建设会专门划分数据域,面向特定的而业务场景,例如把数据域划分为财务域、订单域、员工域,当面向特定主题,例如财务分析报告时,就会专门用到财务主题的数据。
集成,是指数仓需要集成个业务系统的数据源,需要利用集成工具,将分散在各业务系统的数据源,通过ETL工具,把数据统一存储到数据仓库,基于重新数据建模,将数据进行重新组织。
稳定,是数据仓库的数据为了保证真实性,一般不会发生变化。
反映历史变化,由于数仓数据具有稳定性,又把数据通过实时和定时的方式,抽取到数仓,其存储了若干年的总数据,通过数仓可了解某个主题的历史变化情况。
数仓经历了传统数仓、大数据数仓、实时数仓、多模实时数仓等阶段,下面介绍下传统数仓的局限性。
传统数仓,是基于关系型数据库实现,现在有部分企业,还在使用Mysql做数仓,那么传统数仓有哪些局限性呢?
第一,无法满足海量数据的存储需求
传统关系型数仓水平扩展难,纵向扩展有限,没法存储海量数据,如果无限扩展存储空间,则数据查询、数据分析等性能方面,将令人发狂
第二,无法处理多种类型的数据
关系型数仓只能处理结构化数据,在大数据时代,除了结构化,还有大量半结构化,非结构化,其中非结构化数据占到90%,传统数仓无法处理半结构化、非结构化数据
第三、计算和处理能力不足
尤其在面对海量数据场景,由于传统数据不支持分布式集群机制,在计算和处理能力上碰到了严重瓶颈。
说到数仓,常常会和数据库联系,下面介绍下数仓和数据库的两个重要的区别。
1、数据的稳定性。
数据库要保证事务机制,任何一条记录只存储当前的值,也就是说新值替换旧值,例如库存表,当卖出一件商品,就会实时减少一件库存量,然而数据仓库为了反映历史变化,其并不会实时更新库存数量,集成到数仓的数据,一般就不会再更改。
2、应用场景
数据库是用于事务支撑和实体、事件数据的存储,支撑业务系统的实体和业务过程的实现,用于OLTP。而数据仓库仅仅用来做数据分析,支撑企业的经营决策。
如果需要了解数据库和数据仓库的详细区别,可阅读笔者之前分享过的文章《数据仓库、数据湖、数据中台三者的区别》
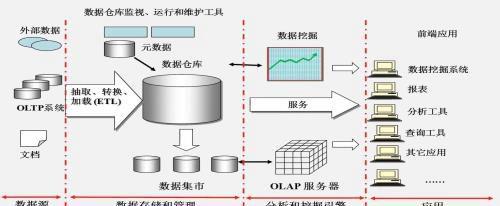
接下来给大伙分享下通用的数仓架构
图 通用数据仓库架构
数据仓库架构分为五部分
【数据源】
散落在各业务系统中的数据,当需要集成数据源时,需从数据分析需求,推断需要集成哪些数据源
【ETL】
需要将数据源集成至数仓,会涉及到抽取,转换,加载等操作。当前开源的数据传输工具有Canal、DataX、sqoop。
【数据存储和管理】
相当于数据仓库系统,完整的数仓系统,需包含管理、监视运维等内容
【分析和挖掘引擎】
数仓作为数据的存储,其上需要建立计算引擎和挖掘引擎,例如离线计算MR,实时计算Flink,Spark streaming, 机器学习Mahout、spark Mlib,Flink ML等。
【数据应用】
数据经过集成、存储、计算和挖掘后,最终的目的是为了消费,赋能业务,赋能分析决策,数据应用主要是搜索、查询等方面,具体表现形式有BI报表、分析,还会有一些数据智能应用。
好了,今天分分享就到这,希望对大家有帮助,感谢关注
本文内容由小畅整理编辑!