> 电脑数码
kafka消费者如何保证消息不丢失(kafka如何避免消息丢失)
导语:Kafka如何保证消息不丢失、消费数据模式
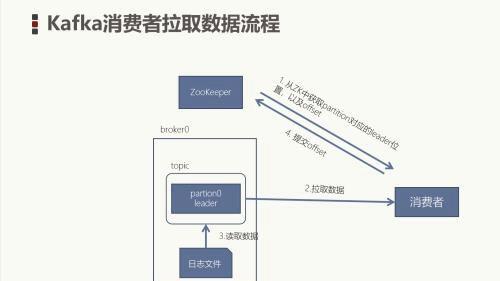
消费模式kafka采用拉取模型,由消费者自己记录消费状态,每个消费者互相独立地顺序拉取每个分区的消息消费者可以按照任意的顺序消费消息。比如,消费者可以重置到旧的偏移量,重新处理之前已经消费过的消息;或者直接跳到最近的位置,从当前的时刻开始消费Kafka消费数据流程Kafka消费数据流程
每个consumer都可以根据分配策略(默认RangeAssignor),获得要消费的分区获取到consumer对应的offset(默认从ZK中获取上一次消费的offset)找到该分区的leader,拉取数据消费者提交offsetKafka的数据存储形式Kafka的数据存储形式
一个topic由多个分区组成一个分区(partition)由多个segment(段)组成一个segment(段)由多个文件组成(log、index、timeindex)消息不丢失机制1、broker数据不丢失生产者通过分区的leader写入数据后,所有在ISR中follower都会从leader中复制数据,这样,可以确保即使leader崩溃了,其他的follower的数据仍然是可用的
2、生产者数据不丢失生产者连接leader写入数据时,可以通过ACK机制来确保数据已经成功写入。ACK机制有三个可选配置1 配置ACK响应要求为 -1 时 —— 表示所有的节点都收到数据(leader和follower都接收到数据)
2 配置ACK响应要求为 1 时 —— 表示leader收到数据
3 配置ACK影响要求为 0 时 —— 生产者只负责发送数据,不关心数据是否丢失(这种情况可能会产生数据丢失,但性能是最好的)
生产者可以采用同步和异步两种方式发送数据同步:发送一批数据给kafka后,等待kafka返回结果
异步:发送一批数据给kafka,只是提供一个回调函数。
说明:如果broker迟迟不给ack,而buffer又满了,开发者可以设置是否直接清空buffer中的数据。
3、消费者数据不丢失在消费者消费数据的时候,只要每个消费者记录好offset值即可,就能保证数据不丢失。
数据积压Kafka消费者消费数据的速度是非常快的,但如果由于处理Kafka消息时,由于有一些外部IO、或者是产生网络拥堵,就会造成Kafka中的数据积压(或称为数据堆积)。如果数据一直积压,会导致数据出来的实时性受到较大影响。
解决数据积压问题当Kafka出现数据积压问题时,首先要找到数据积压的原因。以下是在企业中出现数据积压的几类场景。
1.数据写入MySQL失败2.因为网络延迟消费失败本文内容由小荣整理编辑!