padas数据分组(padas分组后如何分别保存)
导语:「干货教程6」Pandas如何分组「推荐」
03
Groupby:分-治-合
group by具体来说就是分为3步骤,分-治-合,具体来说:
分:基于一定标准,splitting数据成为不同组治:将函数功能应用在每个独立的组上合:收集结果到一个数据结构上分和合按照字面理解就可,但是“治”又是怎么理解,进一步将治分为3件事:
聚合操作,比如统计每组的个数,总和,平均值转换操作,对每个组进行标准化,依据其他组队个别组的NaN值填充过滤操作,忽略一些组,比如个数不够指定大小的下面详细说下,分,治,这两步操作。合地话就是映射为具体的某个数据结构。
04
分(splitting)
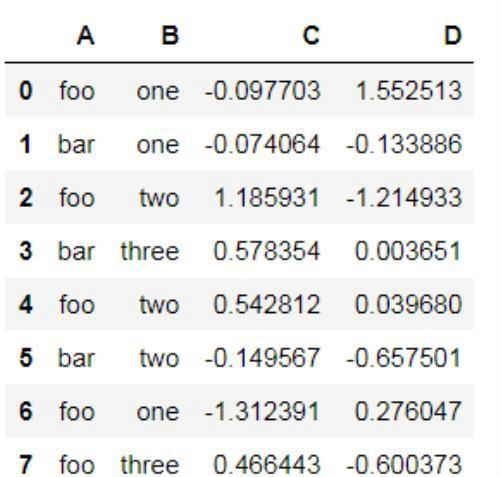
分组就是根据默认的索引映射为不同索引取值的分组名称,来看如下所示的DataFrame实例df_data,可以按照多种方式对它分组,直接调用groupby接口,
df_data.groupby('A')默认是按照axis=0分组的(行),如果按照列,修改轴,即
df_data.groupby('A' , axis=1)也可以按照多个列分组,比如:
df_data.groupby([ 'A', 'B'] )05
选择分组
分组后返回的对象类型为:DataFrameGroupBy,我们看下按照列标签'A'分组后,因为'A'的可能取值为:foo, bar ,所以分为了两组,通过DataFrameGroupBy的get_group可以取得对应的组内行,如下图所示,
agroup = df.groupby('A')agroup.get_group('foo')
同样的方法,看下bar组包括的行:
agroup = df.groupby('A')agroup.get_group('bar')
如果我们想看下每组的第一行,可以调用 first(),可以看到是每个分组的第一个,last()显示每组的最后一个:
agroup.first()
06
治:分组上的操作
对分组上的操作,最直接的是使用aggregate操作,如下,求出每个分组上对应列的总和,大家可以根据上面的分组情况,对应验证:
agroup = df.groupby('A')agroup.aggregate(np.sum)
如果根据两个字段的组合进行分组,如下所示,为对应分组的总和,
abgroup = df.groupby(['A','B'])abgroup.aggregate(np.sum)
查询对应每个分组的个数,返回的是Series实例:
abgroup.size()
如果需要查看,分组foo, one 的个数,如下,得到个数 2.
abgroup.size()['foo']['one']获得每个分组的统计信息,调用describe接口,如下所示:
abgroup.describe()
一次应用多个函数:
agroup = df.groupby('A')agroup.agg([np.sum, np.mean, np.std])
本文内容由小媛整理编辑!