odebuffe(odebuffe面试题)
导语:针对Node的Buffer模块中难理解的API做一次彻底的讲解
上一节我们介绍了Buffer中编码的特点,这篇文章我们介绍一些Buffer的API!
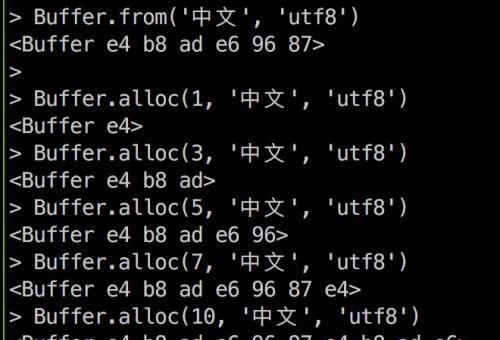
Buffer.alloc(size[, fill[, encoding]])size代表Buffer的长度fill初始化填充的内容encoding代表编码demo1
在demo1中可以看出fill和encoding之间的关系,fill先按照encoding编码成二进制,然后一个字节一个字节的向此方法生成的Buffer中填充,根据长度size,依次循环!
Buffer.from(arrayBuffer[, byteOffset[, length]])demo2
demo2将一个二进制数组[5000, 4000]放入Buffer中生成了<88 a0>,何解啊?因为Buffer实例是Uint8Array的实例,此时相当于把arr放入Uint8Array中,元素一一对应,而Uint8Array每个元素都是8位,最大值是256,所以发生了溢出,根据溢出的算法最终变为了<88 a0>。文章JS操作内存?二进制数组了解一下已经介绍了溢出的算法,可以参考!
如果不想发生溢出,可以使用二进制数组的buffer属性(此时会共享内存):
demo3
可选的byteOffset和length参数指定 arrayBuffer 中与 Buffer 共享的内存范围,如果不使用buffer属性,这两个参数并不会生效,如下:
demo4
读字节流readUInt8/readInt8读取一个字节的有/无符号的整数
demo5
readUInt8直接读取一个字节的二进制readInt8读取8位有符号的二进制,所以有可能会发生溢出,溢出的算法之前已经提到了readInt16BE/readInt16LE/readUInt16BE/readUInt16LE读取两个字节的有/无符号的整数
BE代表大端字节序,高位在前,网络就是这种字节序LE代表小端字节序,低位在前demo6
如demo6中,无符号读取第一个,如果是大端,数值应该是0xff01,如果是小端,数值应该是0x01ff。
readInt16BE/readInt16LE有符号的大小端读取方式和无符号的方式是一样的,不过有可能发生溢出,如demo7所示(溢出算法和之前一致)。
demo7
readInt32BE/readInt32LE/readUInt32BE/readUInt32LE 这四个和16位的读取规则一致,就不细说了。
readIntBE(offset, byteLength)readIntLE(offset, byteLength)readUIntBE(offset, byteLength)readUIntLE(offset, byteLength)offset开始读取之前要跳过的字节数,必须满足0 <= offset <= buf.length - byteLength,byteLength要读取的字节数,必须满足0 < byteLength <= 6。
这四个方法可以完全代替之前的8/16/32位对应的方法,如下demo:
demo8
byteLength代表一次读取的字节数,如果是1就对应8位,2对应16位.....
readDoubleBEreadDoubleLEreadFloatBEreadFloatLE以上四个是读取单双精度浮点数的方法,在使用这四个方法之前,我们需要了解二进制是如何表示单双精度浮点数的,可以参考峰哥的文章《浮点数的二进制表示》。
demo9
demo9是峰哥文章的一个截图,上面那个单精度二进制的结果是0.15626,我们现在推导一下这个结果。
这个单精度是4个字节,先将二进制变成16进制 [0x3e, 0x20, 0x00, 0x00],采用上面的方法读取一下:
demo10
demo10中无论采用大端还是小端读取都是正确的。
个人觉得这里的难点是了解浮点数转化二进制的规则
写字节流如果已经理解了读字节流,其实写字节流是非常简单的!
写字节流的API与上方一致, 只需要将read换成write
举个例子:
demo11
写字节流的时候需要注意数值的范围,如果超出范围会报错。
总结Buffer的讲解就到此结束,这篇文章并不是流水式的讲述Buffer的API,作者主要是把个人认为比较难理解的方法通过例子的方式讲清楚,还有很多没说到的方法应该都是比较简单的,看一下Node文档就明白了!
喜欢我的文章就关注我吧,有问题可以发表评论,我们一起学习,共同成长!
本文内容由快快网络小美创作整理编辑!