流行算法广度优先搜索算法是什么(广度优先搜索算法一般保留全部节点)
导语:流行算法:广度优先搜索算法
一、定义广度优先搜索,也称为宽度优先搜索(BFS, Breadth First Search),广度优先搜索是一层一层地探索空间,是一个针对图和树的遍历算法。广度优先搜索发明于1960左右,最初用于解决迷宫最短路径和网络路由等问题, BFS在求解最短路径或者最短步数上有很多的应用。
BFS算法是很多重要的图的算法的原型,Dijksta单源最短路径算法和Prim最小生成树算法都采用了与广度优先搜索类似的思想。它属于一种盲目搜寻法,目的是系统地展开并检查图中的所有节点,以找寻结果。换句话说,它并不考虑结果的可能位置,彻底地搜索整张图,直到找到结果为止。
搜索的本质其实就是试探问题的所有可能性,在遍历的过程中,最重要的规则即为不重不漏,最经典的广度优先搜索遵循了这个规则。
BFS算法是以遍历所有结点为主要目的的算法,它不一定能遍历所有的路径。
广度优先搜索的实现一般采用open-closed表。一般的实验里,其邻居节点尚未被检验过的节点会被放置在一个被称为open的容器中(例如队列或是链表),而被检验过的节点则被放置在被称为closed 的容器中。
二、回答两类问题第一类问题:从开始结点出发,有前往目标结点的路径吗?
第二类问题:从开始结点出发,前往目标结点的哪条路径最短?
三、实现广度优先方式广度优先遍历图的方式是这样的,一次性访问当前结点的所有未访问的相邻结点,并依次对每个相邻结点执行同样处理。因为要依次对每个相邻顶点执行同样的广度优先访问操作,所以需要借助队列结构来存储当前顶点的相邻顶点。
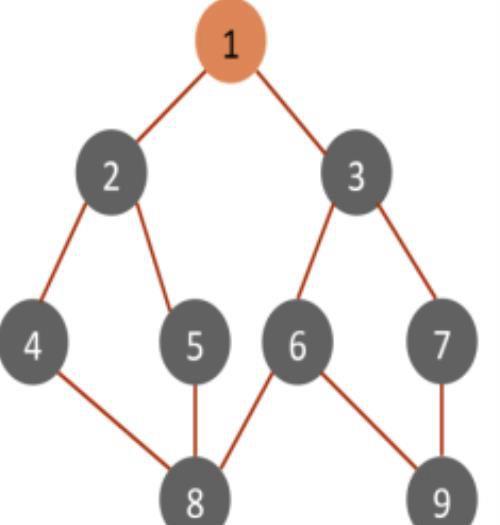
四、演示例子对于图4-1的树而言,BFS方法首先从根结点1开始,其搜索结点顺序是1,2,3,4,5,6,7,8,9。
图4-1
BFS使用队列(queue)来实施算法过程,队列(queue)有着先进先出FIFO(First Input First Output)的特性。
BFS操作步骤如下:
把起始点放入Queue;从queue中取出队列头的结点;找出与此结点邻接的且尚未遍历的点,进行标记,然后全部放入queue中。重复2、3步骤,直到queue为空为止下面结合图4-1的实例,说明BFS的工作过程和原理: (1)将起始结点1放入队列中,标记为已遍历。如图4-2所示。
图4-2
(2)从queue中取出队列头的结点1,找出与结点1邻接的结点2、3,标记为已遍历,然后放入queue中。 如图4-3所示。
图4-3
(3)从queue中取出队列头的结点2,找出与结点2邻接的结点1、4、5,由于结点1已遍历,排除。标记4、5为已遍历,然后放入queue中。如图4-4所示。
图4-4
(4)从queue中取出队列头的结点3,找出与结点3邻接的结点1、6、7,由于结点1已遍历,排除。标记6、7为已遍历,然后放入queue中。如图4-5所示。
图4-5
(5)从queue中取出队列头的结点4,找出与结点4邻接的结点2、8,2属于已遍历点,排除。标记结点8为已遍历,然后放入queue中。 如图4-6所示。
图4-6
(6)从queue中取出队列头的结点5,找出与结点5邻接的结点2、8,2、8均属于已遍历,不作其它操作。如图4-7所示。
图4-7
(7)从queue中取出队列头的结点6,找出与结点6邻接的结点3、8、9,3、8属于已遍历点,排除。标记结点9为已遍历,然后放入queue中。如图4-8所示。
图4-8
(8)从queue中取出队列头的结点7,找出与结点7邻接的结点3、9,3、9属于已遍历点,不作其它操作。如图4-9所示。
图4-9
(9)从queue中取出队列头的结点8,找出与结点8邻接的结点4、5、6,4、5、6属于已遍历点,不作其它操作。如图4-10所示。
图4-10
(10)从queue中取出队列头的结点9,找出与结点9邻接的结点6、7,6、7属于已遍历点,不作其它操作。如图4-11所示。
图4-11
(11)queue为空,BFS遍历结束。
五、广度优先搜索的优缺点优点:
对于解决最短或最少问题特别有效,而且寻找深度小。每个结点只访问一遍,结点总是以最短路径被访问,所以第二次路径确定不会比第一次短。缺点:
内存耗费量大(需要分配大量的数组单元用来存储状态)。六、广度优先搜索与深度优先搜索的区别七、应用图的最小生成树;求解最短路径或者最短步数,应用最多的是在走迷宫上;拓扑排序;其它应用。本文内容由快快网络小心创作整理编辑!