bp算法详细推导(bp算法是什么算法)
导语:一文彻底搞懂BP算法:原理推导+数据演示+项目实战(上篇)
反向传播算法(Backpropagation Algorithm,简称BP算法)是深度学习的重要思想基础,对于初学者来说也是必须要掌握的基础知识!本文希望以一个清晰的脉络和详细的说明,来让读者彻底明白BP算法的原理和计算过程。
全文分为上下两篇,上篇主要介绍BP算法的原理(即公式的推导),介绍完原理之后,我们会将一些具体的数据带入一个简单的三层神经网络中,去完整的体验一遍BP算法的计算过程;下篇是一个项目实战,我们将带着读者一起亲手实现一个BP神经网络(不使用任何第三方的深度学习框架)来解决一个具体的问题。
1. BP算法的推导
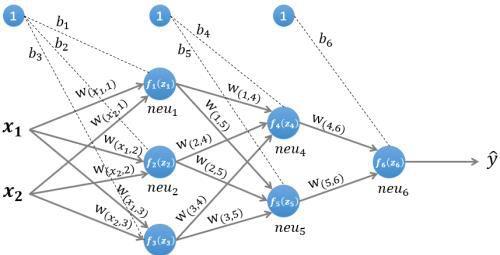
图1 一个简单的三层神经网络
图 1 所示是一个简单的三层(两个隐藏层,一个输出层)神经网络结构,假设我们使用这个神经网络来解决二分类问题,我们给这个网络一个输入样本(x₁,x₂),通过前向运算得到输出y ̂。输出值y ̂的值域为[0,1],例如y ̂的值越接近0,代表该样本是"0"类的可能性越大,反之是"1"类的可能性大。
1.1 前向传播的计算
为了便于理解后续的内容,我们需要先搞清楚前向传播的计算过程,以图1所示的内容为例:
输入的样本为:
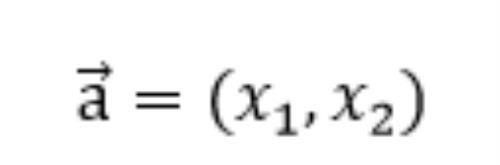
第一层网络的参数为:
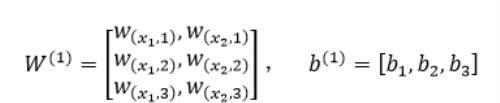
第二层网络的参数为:
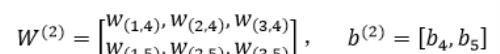
第三层网络的参数为:
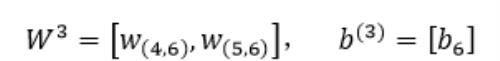
1.1.1 第一层隐藏层的计算
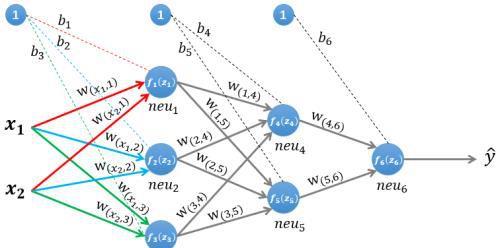
图2 计算第一层隐藏层
第一层隐藏层有三个神经元:neu₁、neu₂和neu₃。该层的输入为:
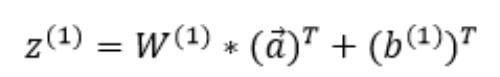
以neu₁神经元为例,则其输入为:
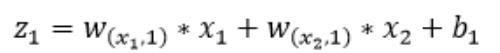
同理有:
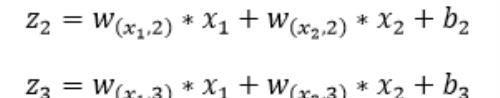
假设我们选择函数f(x)作为该层的激活函数(图1中的激活函数都标了一个下标,一般情况下,同一层的激活函数都是一样的,不同层可以选择不同的激活函数),那么该层的输出为:f₁(z₁)、f₂(z₂)和f₃(z₃)。
1.1.2 第二层隐藏层的计算
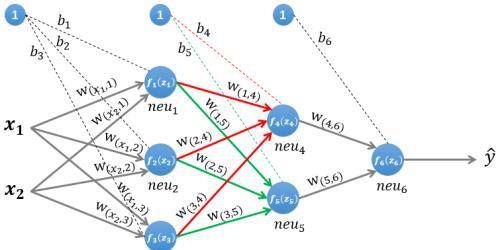
图3 计算第二层隐藏层
第二层隐藏层有两个神经元:neu₄和neu₅。该层的输入为:
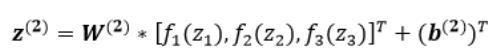
即第二层的输入是第一层的输出乘以第二层的权重,再加上第二层的偏置。因此得到和的输入分别为:
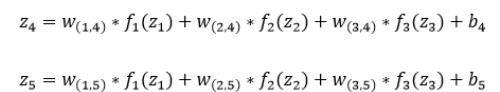
该层的输出分别为:f₄(z₄)和f₅(z₅)。
1.1.3 输出层的计算
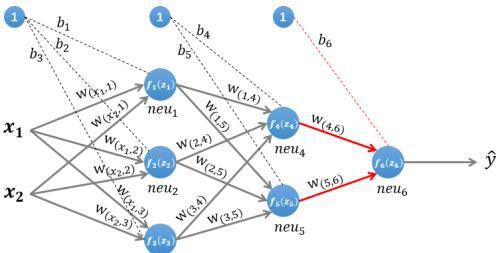
图4 计算输出层
输出层只有一个神经元neu₆:。该层的输入为:
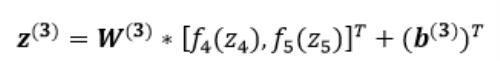
即:
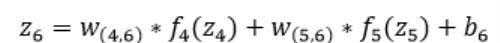
因为该网络要解决的是一个二分类问题,所以输出层的激活函数也可以使用一个Sigmoid型函数,神经网络最后的输出为:f₆(z₆)。
1.2 反向传播的计算
在1.1节里,我们已经了解了数据沿着神经网络前向传播的过程,这一节我们来介绍更重要的反向传播的计算过程。假设我们使用随机梯度下降的方式来学习神经网络的参数,损失函数定义为L(y,y ̂ ),其中 y 是该样本的真实类标。使用梯度下降进行参数的学习,我们必须计算出损失函数关于神经网络中各层参数(权重w和偏置b)的偏导数。


1.2.1 计算偏导数
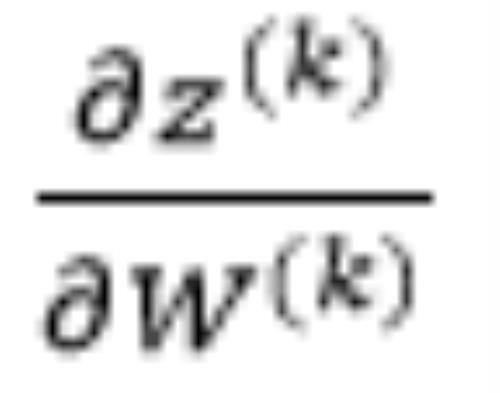
前面说过,第k层神经元的输入为:
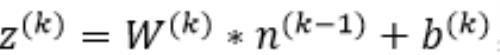
因此可以得到:
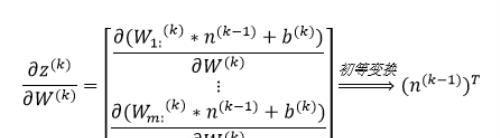
上式中,(W_(m:))^(k)代表第k层神经元的权重矩阵W^k的第m行,(W_(mn))^((k))代表第k层神经元的权重矩阵W^k的第m行中的第n列。
我们以1.1节中的简单神经网络为例,假设我们要计算第一层隐藏层的神经元关于权重矩阵的导数,则有:
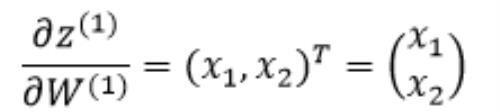
1.2.2 计算偏导数
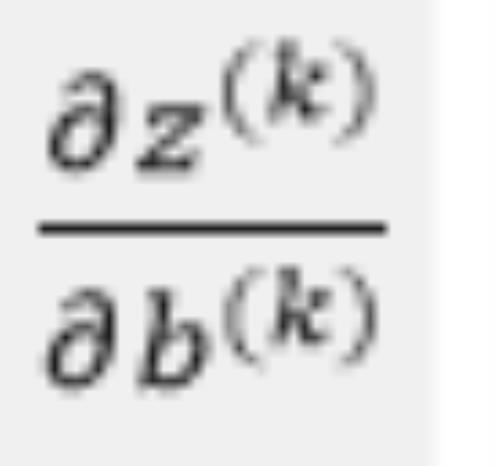
因为偏置b是一个常数项,因此偏导数的计算也很简单:
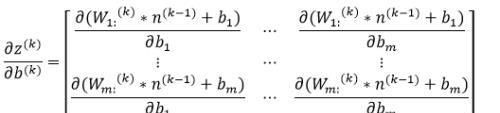
依然以第一层隐藏层的神经元为例,则有:

1.2.3 计算偏导数



下面是基于随机梯度下降更新参数的反向传播算法:

单纯的公式推导看起来有些枯燥,下面我们将实际的数据带入图1所示的神经网络中,完整的计算一遍。
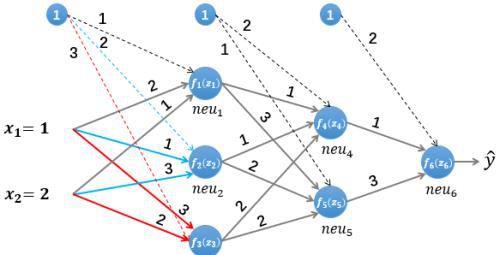
2. 图解BP算法
图5 图解BP算法
我们依然使用如图5所示的简单的神经网络,其中所有参数的初始值如下:
输入的样本为(假设其真实类标为"1"):
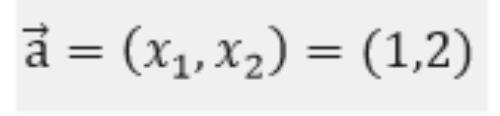
第一层网络的参数为:
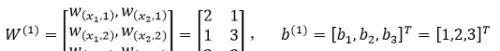
第二层网络的参数为:
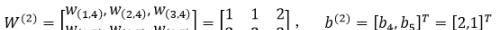
第三层网络的参数为:
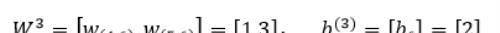
假设所有的激活函数均为Logistic函数:
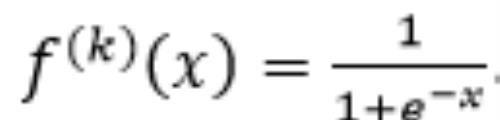
使用均方误差函数作为损失函数:
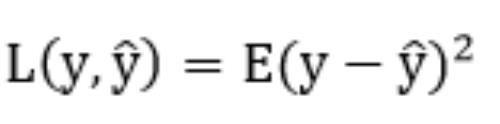
为了方便求导,我们将损失函数简化为:
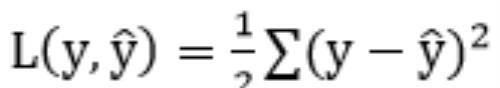
2.1 前向传播
我们首先初始化神经网络的参数,计算第一层神经元:

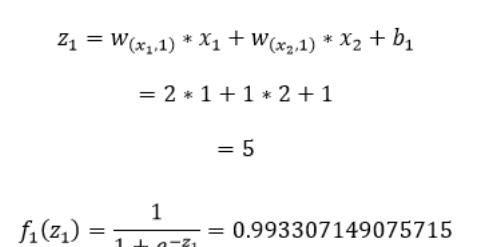
上图中我们计算出了第一层隐藏层的第一个神经元的输入z₁和输出f₁(z₁),同理可以计算第二个和第三个神经元的输入和输出:
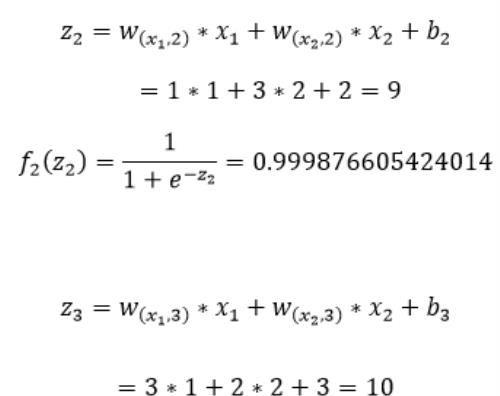

接下来是第二层隐藏层的计算,首先我们计算第二层的第一个神经元的输入z₄和输出f₄(z₄):

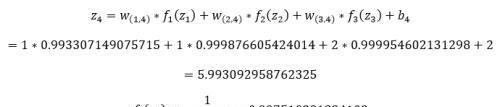
同样方法可以计算该层的第二个神经元的输入z₅和输出f₅(z₅):
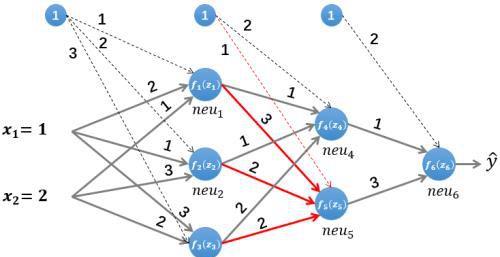

最后计算输出层的输入z₆和输出f₆(z₆):
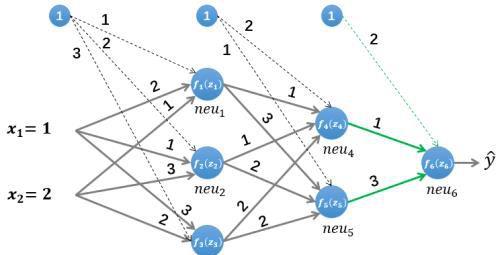

2.2 误差反向传播
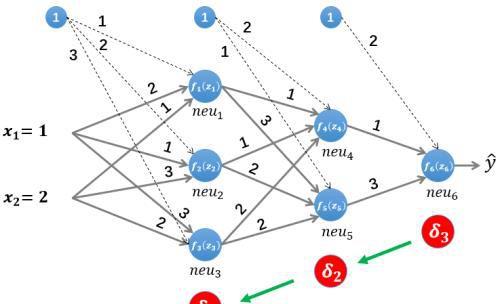

接着计算第二层隐藏层的误差项,根据误差项的计算公式有:
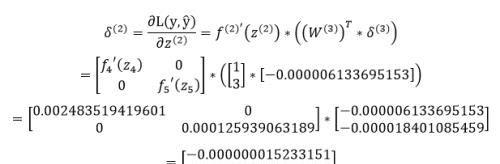
最后是计算第一层隐藏层的误差项:

2.3 更新参数
上一小节中我们已经计算出了每一层的误差项,现在我们要利用每一层的误差项和梯度来更新每一层的参数,权重W和偏置b的更新公式如下:

通常权重W的更新会加上一个正则化项来避免过拟合,这里为了简化计算,我们省去了正则化项。上式中的是学习率,我们设其值为0.1。参数更新的计算相对简单,每一层的计算方式都相同,因此本文仅演示第一层隐藏层的参数更新:

3. 小结
至此,我们已经完整介绍了BP算法的原理,并使用具体的数值做了计算。在下篇中,我们将带着读者一起亲手实现一个BP神经网络(不使用任何第三方的深度学习框架),敬请期待!
免责声明:本站部份内容由优秀作者和原创用户编辑投稿,本站仅提供存储服务,不拥有所有权,不承担法律责任。若涉嫌侵权/违法的,请与我联系,一经查实立刻删除内容。本文内容由快快网络小余创作整理编辑!