一个汉字占几个字节(一个汉字占多少长度)
导语:一个汉字占多少个字节,我错了20年
当我上第一节计算机课的时候,我的电脑老师跟我说,一个英文字符是1个字节,一个中文是2个字节。这么多年来,我对此一直坚信不移,相信很多人也是这么觉得的,但是,真实情况下是这么一回事么?

要了解这个问题,我们首先得从字节说起,什么是字节呢?要知道,在计算中,底层都是晶体管的开关和关闭状态,我们把一个表示开关状态的称之为位,把八位称之为一个字节,也就是一个字节可以表示(00000000-11111111),也就是0到255。为什么是8位呢?因为字符实际上还不到128个,按道理7位就够了,一个说法是程序员也比较迷信,认为7是个不吉利的数字,另一种说法,8刚好是2^3的方,更容易计算机去理解。
ASCII(美国信息交换标准代码)是美国人用来对拉丁字符进行的编码。因为计算机是美国人发明的,所以他们也没考虑其他国家可能也要用到计算机。下面是一个ASCII编码的对应表。
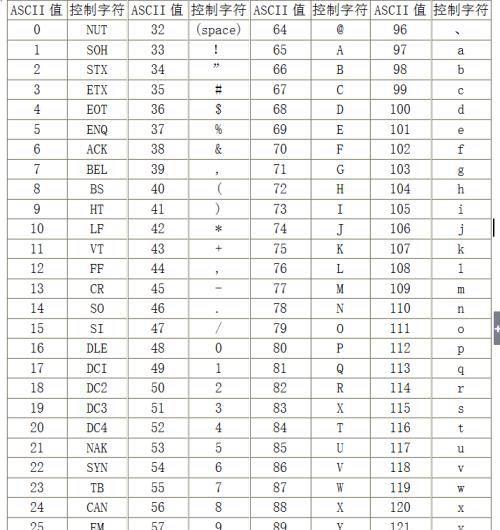
后来随着计算机的发展,一些不是拉丁字母的国家也开始用计算机了,发现一个字节只能表示256个字符,这明显不够,像我们汉字博大精深,常用的都有几千个,于是常见的中文的编码GB2312(国家简体中文字符集)就出现了。GB2312用两个字节来表示一个汉字,例如学习的学,对应的编码就是10010010 0000111。这也就是小时候我们的电脑老师跟我们说的,在计算机中,英文字母占1个字节,汉字占2个字节。
随着互联网的继续发展,不同的国家,不同的语言都用着不同的编码,每当不同的人进行交流,都要先知道对方用的是什么编码,这往往就造成了沟通的成本,而且经常因为编码错误造成各种乌龙。于是,国际上就定一了一种全新的编码方法,全世界所有的字符、文字都有对应的一个编码,以后,就不需要转化成不同的编码了,这便是Unicode编码。Unicode编码使用4个字节来描述一个字符,每个字节8位,理论上就能表示2^32个不同的字符,全世界的字符都没这么多。
但随之又引来一个问题,原先一个英文字符需要1个字节,一个中文需要两个字节,现在需要4个字节,相当于存储变大了。这给网络传输、系统存储都带来了一定的成本。这个时候,人们觉得压缩一下,于是提出了UTF8,UTF16这样的表示方法,UTF8我们最经常使用,怎么表示呢?对于一个汉字,例如上述学习的学字在Unicode编码中表示为00000000 00000000 01011011 01100110。很明显,前面字节都是0,非常的浪费,最好是能够把它压缩起来,又能让别人知道它原来对应的就是四个字节,怎么办呢?UTF8就是为了解决这个问题,对于原来是双字符的中文,会变成3个字节,第一个字节以1110开头,后面两个以10开头。剩下的16位分摊到这3个字节当中。图中便是这个学字如何从Unicode编码转成utf8编码。

好了,到这里相信你就已经明白了,一个汉字占多少个字节,是跟汉字的编码有关系,在GB2312或者GBK编码中,大部分汉字为2字节(部分3个),在UTF8编码中,大部分汉字为3字节(部分为4个)。怎么样,学到了么?是不是很有意思?
免责声明:本站部份内容由优秀作者和原创用户编辑投稿,本站仅提供存储服务,不拥有所有权,不承担法律责任。若涉嫌侵权/违法的,请与我联系,一经查实立刻删除内容。本文内容由快快网络小里创作整理编辑!