edis高性能(edis的高可用和高性能是怎么实现的)
导语:Redis02-Redis高性能与epoll
Redis为何如此之快
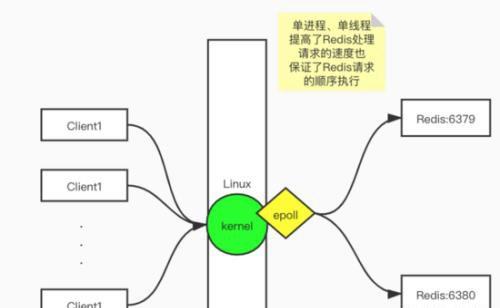
Redis基本是内存操作,所以速度很快内存: 1. 寻址时间:纳秒级别ns 2. 带宽:很大 磁盘: 1. 寻址时间:毫秒级别ms 2. 带宽:G/M 磁盘比内存寻址慢了10W倍以上,所以单机Redis能支持每秒10W以上的请求可能很多人认为要想系统处理速度快不是应该使用多线程技术。但其实Redis的数据都是放在内存中,查询存储都延时都非常小,是纳秒级别的,所以如果使用多线程,就需要加锁,系统资源还需要耗费在线程之间上下文切换上面,反而会影响性能。单进程、单线程天生就保证了请求的顺序执行,不需要加锁,也没有了不必要的上下文切换,因此可以将硬件的性能发挥到极致
这3个条件不是相互独立的,特别是第一条,如果请求都是耗时的,采用单线程吞吐量及性能可想而知了。应该说Redis为特殊的场景选择了合适的技术方案。
Epoll的高性能如何成就RedisI/O模型 BIO、NIO、多路复用I/O、AIO1. 阻塞I/O(Blocking I/O BIO)应用程序进程/线程如果发起1K个请求,则开启1K个socket文件描述符,socket在等待内核返回数据时是阻塞式的,数据未准备好就一直阻塞等待,一次只会返回一个socket结果,直到返回数据后才等待下一个socket的返回
2. 轮询非阻塞I/O(Non-Blocking I/O NIO)应用进程如果发起1K个请求,则在用户空间不停轮询这1K个socket文件描述符,查看是否有结果返回。这种方法虽然不阻塞,但是效率太低,有大量无效的循环
3. 多路复用I/O(Multiplexing I/O)select: 能打开的文件描述符个数有限(最多1024个),如果有1K个请求,用户进程每次都要把1K个文件描述符发送给内核,内核在内部轮询后将可读描述符返回,用户进程再依次读取。因为文件描述符(fd)相关数据需要在用户态和内核态之间拷来拷去,所以性能还是比较低
poll:可打开的文件描述符数量提高,但性能仍然不够
epoll(Linux下多为该技术):用户态和内核态之间不用文件描述符(fd)的拷贝,而是通过mmap技术开辟共享空间,所有fd用红黑树存储,有返回结果的fd放在链表中,用户进程通过链表读取返回结果,伪异步I/O,性能较高。epoll分为水平触发和边缘出发两种模式,ET是边缘触发,LT是水平触发,一个表示只有在变化的边际触发,一个表示在某个阶段都会触发
4. 异步I/O AIOAIO:异步I/O,性能最高,但是使用非常复杂,不是很常用(windows系统中多见)
免责声明:本站部份内容由优秀作者和原创用户编辑投稿,本站仅提供存储服务,不拥有所有权,不承担法律责任。若涉嫌侵权/违法的,请反馈,一经查实立刻删除内容。本文内容由快快网络小欣创作整理编辑!