近水楼台先得月是什么意思(近水楼台先得月中的近水楼台是什么意思)
导语:“近水楼台先得月”——理解KNN算法

古语云:“近水楼台先得月”,意思是临近在水边的楼台就能优先得到月亮的光芒,也比喻由于接近某些人或事物而抢先得到某种利益或便利。还有一句类似的话:“远亲不如近邻”,说的是人在有需要时,邻居比远处的亲戚更加能获得支持和帮助。在人工智能领域,有一种算法,非常贴近上述的形象比喻,这就是KNN算法,即K最近邻算法(K-NearestNeighbors,简称KNN),它是一个比较简单的机器学习算法,也是一个理论上比较成熟的、运用基于样本估计的最大后验概率规则的判别方法。本文对KNN算法做一个通俗易懂的介绍,并通过python进行编码示范,让读者朋友对该算法有较好的理解。
“牛”还是“羊”——理解KNN
K最近邻算法的比较贴近的一个比喻场景是:一个牧场里,放养着许多牛和羊,它们交叉聚集生活在一起,有时某只动物自己都可能分不清自己是牛还是羊。按照K最近邻算法,它判别自己是牛或者羊的依据是——“我”周边离“我”最近的类别(牛或者羊),且在一定范围内是数量最多的类别,那“我”就是这个类别。归结到K最近邻算法中,就是在一个数据集中,新的数据点离哪一类最近且一定范围内最多,就和这一类属于同一类。

其中,这个一定范围就是邻居们(Neighbors)的数量,也就是K最近邻算法的“K”这个字母代表的数量(最近邻的个数)。在人工智能领域,大家所熟知的scikit-learn库中,K最近邻算法的K值可以通过n_neighbors参数来调节的,默认值是5。
“近水楼台”——KNN预测实战
“近水楼台先得月”可以很好地诠释KNN算法,下面我们进行一个KNN算法的实际应用,以方便读者更好地理解KNN算法。
当今每届大学生在毕业前一年都非常关注研究生考试,能进入硕士级别进一步深造,也是大多数学生所渴望的,本文将模拟某年部分硕士研究生的入学考试数据集,通过python编程演练一个KNN算法机器学习的建模、训练、预测过程,展示KNN算法的效果。
一、了解数据集
我们采用的数据集包含如下字段:
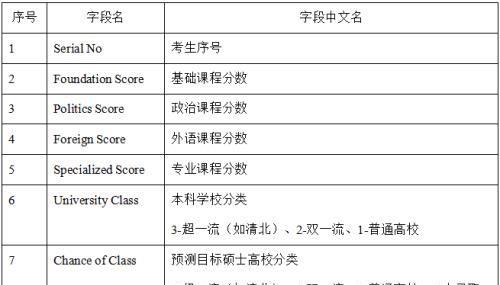
其中,2、3、4、5,分别是研究生入学考试的基础课程、政治课程、外语课程、专业课程的分数。
6是考试学生的本科学校分类,分类粗略的分为三级:3-超一流(如清北)、2-双一流、1-普通高校。
7是考试学生的目标硕士高校学校的分类,分类粗略的分为四级:3-超一流(如清北)、2-双一流、1-普通高校、0-表示未被录取。
二、导入和查看、准备数据集
使用pandas加载硕士研究生入学成绩信息数据集
data= pd.read_csv(&39;)
查看数据特征的统计信息
data.describe()
输出结果如下:

上表说明:这个数据集总共有500条记录,其中基础课程的最高分和最低分是125.7和67.1,政治课程的最高分和最低分是91.8和41.1,外语课的最高分和最低分是91.7和42.2,专业课程的最高分和最低分是133.4和29.2。
下面的代码针对数据集做预处理:
39;SerialNo&把去掉预测目标Chanceof Class后的数据集作为训练数据集X
X= data.drop([&39;], axis = 1)
39;Chance of Class&导入数据集拆分工具
fromsklearn.model_selection import train_test_split
导入用于分类的KNN模型
fromsklearn.neighbors import KNeighborsClassifier
Clf_KNN= KNeighborsClassifier()
39;auto&39;minkowski&39;uniform&打印模型的得分
print(&39;.format(Clf_KNN.score(X_test,y_test)))
print(&39;.format(Clf_KNN.score(X_train,y_train)))
输出结果为:
验证数据集得分:0.81
训练数据集得分:0.87
可以看出模型的训练集和验证集的评估分值都在0.80分以上,模型训练的效果还算不错。
四、预测新成绩的分类
现在有A、B、C三位同学都进行了研究生入学模拟考试,他们的成绩和本科学校分别是:

我们可以利用上面步骤建立的KNN模型来预测一下,看看他们目前的考试成绩能够进入研究生高校的类别是哪些:是成功登上清华北大的超一流神圣殿堂或者普通高校,还是遗憾地铩羽而归。经过这样的预测后,相信他们也会有一定的信心或者更加强化自身的学习力度,力争能考入心仪的理想学校。
下面使用python代码利用前面已经建好的KNN模型,对三位同学的研究生成绩的入学结果进行预测:
使用.KNN模型对A同学的入学可能分类进行预测
pred_A= Clf_KNN.predict(X_A)
使用.KNN模型对B同学的入学可能分类进行预测
pred_B= Clf_KNN.predict(X_B)
使用.KNN模型对C同学的入学可能分类进行预测
pred_C= Clf_KNN.predict(X_C)
print()
print(.format(pred_A))
print(.format(pred_B))
print(.format(pred_C))
输出结果如下:
K最近邻算法模型预测分类结果如下:
A同学的分类结果:[1]
B同学的分类结果:[3]
C同学的分类结果:[0]
以上结果说明,如果按他们的模拟考试成绩,A同学分类预测结果为“1-普通高校”,即KNN模型预测他能够考入一般的普通高校的研究生;B同学分类预测结果为“3-超一流高校(如清北)”,即KNN模型预测他能进入清北超一流殿堂,值得庆祝;C同学分类预测结果为“0-未被录取”,很遗憾,KNN模型预测他成绩不理想,无法考上研究生。
通过这个数据集和例子可以得出一定的推论:考试成绩好且在超一流高校读本科的学生,更容易被超一流的高校(如清北)的硕士学位录取,超一流高校(如清北)的学生可以说是“近水楼台”,比其他学生更容易“先得月”,也比较好地诠释了KNN算法的工作原理。
结语
K最近邻算法(KNN)可以说是一个非常经典、原理十分容易理解的算法。本文利用KNN算法解决了一个研究生入学考试成绩的被录取高校的分类预测问题,其实,K最近算法不仅能够进行分类预测,也可以用于回归,原理和其用于分类是相同的。
另外,利用KNN算法进行机器学习的过程中,对K值(Neighbors的数量)的选择会对算法的结果产生重大影响。K值较小意味着只有与输入实例较近的训练实例才会对预测结果起作用,但容易发生过拟合;如果K值较大,优点是可以减少学习的估计误差,但缺点是学习的近似误差增大。有兴趣的读者朋友可以在上述Python代码中修改K值,看看是否能得到不同的预测结果。
免责声明:本站部份内容由优秀作者和原创用户编辑投稿,本站仅提供存储服务,不拥有所有权,不承担法律责任。若涉嫌侵权/违法的,请反馈,一经查实立刻删除内容。本文内容由快快网络小春创作整理编辑!