语音识别原理 五分钟就能弄懂
首先,我们知道声音实际上是一种波。常见的mp3、wmv等格式都是压缩格式,必须转成非压缩的纯波形文件来处理,比如windows pcm文件,也就是俗称的wav文件。wav文件里存储的除了一个文件头以外,就是声音波形的一个个点了。
在开始语音识别之前,有时需要把首尾端的静音切除,降低对后续步骤造成的干扰。这个静音切除的操作一般称为vad,需要用到信号处理的一些技术。要对声音进行分析,需要对声音分帧,也就是把声音切开成一小段一小段,每小段称为一帧。分帧操作一般不是简单的切开,而是使用移动窗函数来实现,这里不详述。帧与帧之间一般是有交叠的。
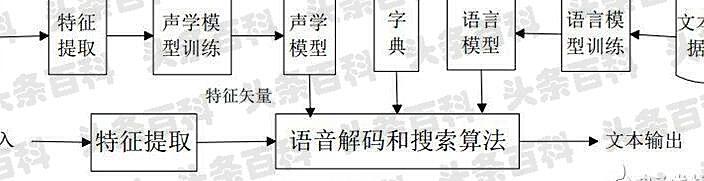
每帧的长度为25毫秒,每两帧之间有25-10=15毫秒的交叠。我们称为以帧长25ms、帧移10ms分帧。每帧的长度为25毫秒,每两帧之间有25-10=15毫秒的交叠。我们称为以帧长25ms、帧移10ms分帧。
分帧后,语音就变成了很多小段。但波形在时域上几乎没有描述能力,因此必须将波形作变换。常见的一种变换方法是提取mfcc特征,根据人耳的生理特性,把每一帧波形变成一个多维向量,可以简单地理解为这个向量包含了这帧语音的内容信息。这个过程叫做声学特征提取。实际应用中,这一步有很多细节,声学特征也不止有mfcc这一种,具体这里不讲。
至此,声音就成了一个12行(假设声学特征是12维)、n列的一个矩阵,称之为观察序列,这里n为总帧数。观察序列如下图所示,图中,每一帧都用一个12维的向量表示,色块的颜色深浅表示向量值的大小。
接下来就要介绍怎样把这个矩阵变成文本了。首先要介绍两个概念:音素:单词的发音由音素构成。对英语,一种常用的音素集是卡内基梅隆大学的一套由39个音素构成的音素集,参见the cmu pronouncing dictionary。汉语一般直接用全部声母和韵母作为音素集,另外汉语识别还分有调无调,不详述。状态:这里理解成比音素更细致的语音单位就行啦。通常把一个音素划分成3个状态。
语音识别是怎么工作的呢?实际上一点都不神秘,无非是:第一步,把帧识别成状态(难点);第二步,把状态组合成音素;第三步,把音素组合成单词。