padas如何处理缺失值(padas缺失值用平均值代替)
导语:Pandas中的缺失值处理

相信大家在处理数据的时候经常会发现有一些数据的缺失,这个时候便会很头大,因为有时候的缺失的数据是本来就没有的,这些数据不管就好了,有的数据虽然没有,但是也可以根据一些数据推算出来这个数据是多少然后给它填上,但是有的数据缺失是随机缺失的完全不知道应该怎么处理,所以呢今天我就带大家了解一下数据中的缺失值以及如何对缺失值进行处理。
读取数据相信大家在使用python读取数据的时候会出现这种报错的情况。
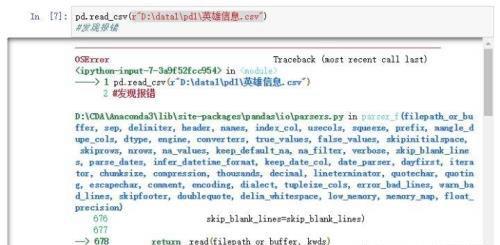
这种情况是因为文件名中有中文,遇到这种情况第一种方式就是讲文件名改为英文,或者这样处理可以。
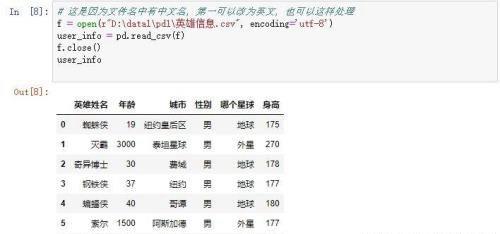
先使用open打开,然后赋值给变量,然后关闭掉文件,使用被赋值的变量就可以了。
二、处理缺失值
1、什么是缺失值
俗话说知己知彼,百战百胜,在处理缺失值之前我们首先要了解一下什么是缺失值? 直观上理解,缺失值表示的是“缺失的数据”。可以思考一个问题:是什么原因造成的缺失值呢?其实有很多原因,实际生活中可能由于有的数据不全所以导致数据缺失,也有可能由于误操作导致数据缺失,又或者人为地造成数据缺失,但是主要的还是分为机械原因和人为原因。
机械原因是由于机械原因导致的数据收集或保存的失败造成的数据缺失,比如数据存储的失败,存储器损坏,机械故障导致某段时间数据未能收集(对于定时数据采集而言)。
人为原因是由于人的主观失误、历史局限或有意隐瞒造成的数据缺失,比如,在市场调查中被访人拒绝透露相关问题的答案,或者回答的问题是无效的,数据录入人员失误漏录了数据
缺失值从缺失的分布来讲可以分为完全随机缺失,随机缺失和完全非随机缺失。
完全随机缺失(missing completely at random,MCAR)指的是数据的缺失是随机的,数据的缺失不依赖于任何不完全变量或完全变量。随机缺失(missing at random,MAR)指的是数据的缺失不是完全随机的,即该类数据的缺失依赖于其他完全变量。完全非随机缺失(missing not at random,MNAR)指的是数据的缺失依赖于不完全变量自身。缺失值从缺失值的所属属性来讲可以分为单值缺失,任意缺失和单调缺失。
单值缺失:如果所有的缺失值都是同一属性,那么这种缺失成为单值缺失。任意缺失:如果缺失值属于不同的属性,称为任意缺失。单调缺失:对于时间序列类的数据,可能存在随着时间的缺失,这种缺失称为单调缺失在Python中缺失值被认为是None、np.nan、NaT的形式。
原理性的东西我们就说这么多,下面我们进入代码部门,首先我们人为的造成一些数据的缺失
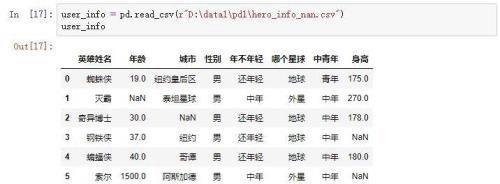
然后我们生成一列英雄们的生日的数据列
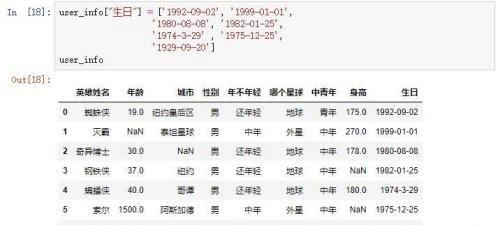
查看数据表的信息。

2、转换数据列的类型
这个时候我们通过info()方法发现生日列的类型是object的,需要将生日列的类型通过to_datetime()转换为日期型
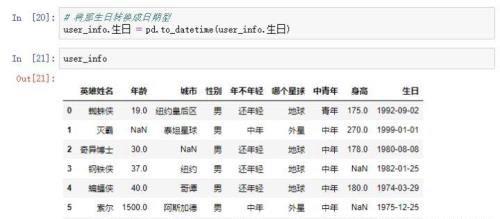
3、掩码提取空值
首先使用isnull()或者notnull()来查看是否缺失

Isnull()是将缺失值判断为True,非缺失值判断为False
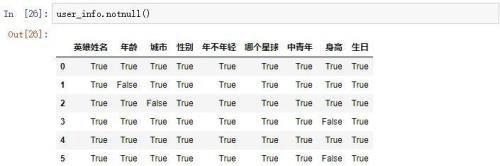
Notnull()将缺失值判断为False,非缺失值判断为True
将有空值的行提取出来 反之将非空行的数据提取出来
反之将非空行的数据提取出来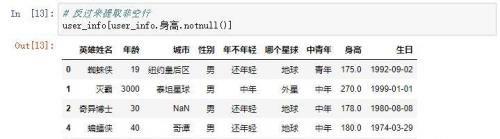 掩码的其他用处
掩码的其他用处4.1、将不是地球的英雄提取出来
首先将那个星球的列名改为星球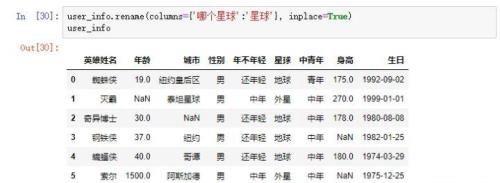 然后将外星球的英雄提取出来。
然后将外星球的英雄提取出来。
4.2、将1980年之后出生的英雄提取出来
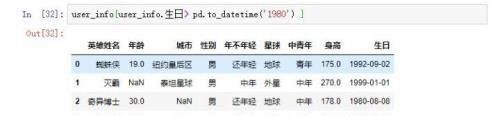
4.3、将1988年1月1号之前出生的英雄提取出来

5、丢弃缺失值
既然在数据中有缺失值了,常见的一种处理办法就是丢弃缺失值。使用 dropna 方法可以丢弃缺失值。
user_info.dropna(axis=0,how='any',thresh=None,subset=None,inplace=False)
seriese使用dropna比较简单,对于DataFrame 来说,可以设置更多的参数。
axis 参数用于控制行或列,跟其他不一样的是,axis=0 (默认)表示操作行,axis=1 表示操作列。
how 参数可选的值为 any(默认) 或者 all。any 表示一行/列有任意元素为空时即丢弃,all 一行/列所有值都为空时才丢弃。subset 参数表示删除时只考虑的索引或列名。thresh参数的类型为整数,它的作用是,比如 thresh=3,会在一行/列中至少有 3 个非空值时将其保留。
一列数据中只要存在一个空值就删除掉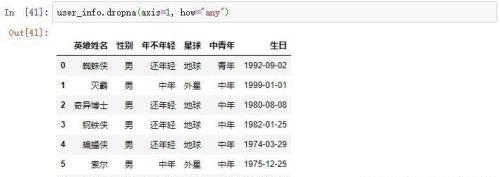
从结果可以看出,身高列和城市列都存在空值,这样就被删除掉了。
一行数据中只要城市和性别出现空值就删除掉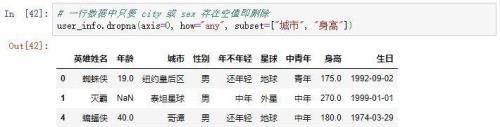
从结果可以看出,钢铁侠、索尔因为身高出现空值而被删除这一行的数据,奇异博士因为城市出现空值而被删除一行的数据,灭霸是年龄出现了空值,但是年龄这一列并未做为删除的条件所以没有被删除掉数据。
三、填充缺失值
除了可以丢弃缺失值外,也可以填充缺失值,最常见的是使用fillna完成填充。Fillna这个名字一看就是用来填充缺失值得嘛。
1、固定值填充
填充缺失值时,常见的一种方式是使用一个标量来填充。比如我们可以将缺失的年龄都填充为0。
将英雄们的身高填充为0
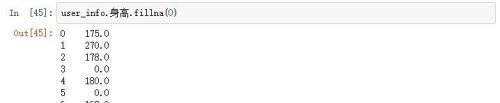
当然在身高列填充0显然是不规范的,咱们这里只做演示使用,大家在实际的处理数据的时候还是要跟数据结合起来在选择填充的标量。
2、上下文填充
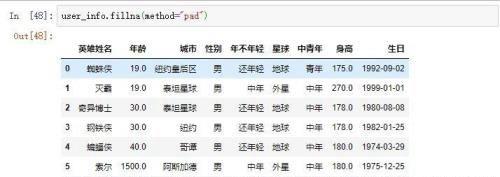
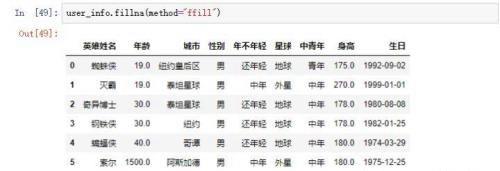
除了可以使用标量来填充之外,还可以使用前一个或后一个有效值来填充。设置参数method=’pad’或method=’ffill’可以使用前一个有效值来填充。
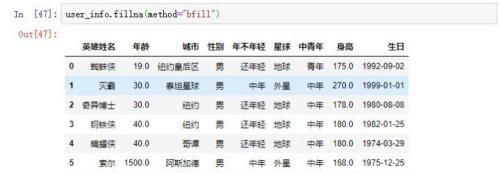
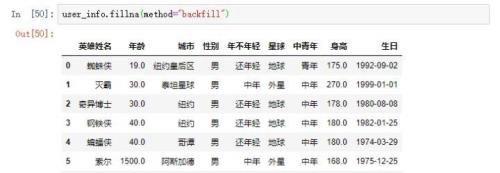
设置参method='bfill'或method='backfill'可以使用后一个有效值来填充。
除了通过fillna方法来填充缺失值外,还可以通过interpolate方法来填充。默认情况下使用线性差值,可以是设置method参数来改变方式。
3、替换缺失值
现在大家想一想,到底什么才是缺失值呢,不要以为我前边说过的那些None、np.nan、NaT这些是缺失值,这些在Pandas中被认为是缺失值,但是呢,在我们活生生的人眼中,某些异常值也会被当成缺失值来处理。
例如,在我们的存储的用户信息中,假定我们限定用户都是青年,出现了年龄为40的,我们就可以认为这是一个异常值。
再比如,我们都知道性别分为男性(male)和女性(female),在记录用户性别的时候,对于未知的用户性别都记为了“unknown”,很明显,我们也可以认为“unknown”是缺失值。
除了这些,有时会也会出现一些空白的字符串,这些也可以认为是缺失值。对于上面的这一系列问题,我们可以使用replace方法来替换缺失值。
假设我们现在是一个地球流浪者收容组织,不允许外星人的存在,那么英雄现在已经存在了,打又打不过,但是又不能违反组织的规定,那怎么办呢,那就把这些惹不起的外星人定义成黑户,也就是空值,不知道他们的星球属性,睁一只眼闭一只眼。 这个时候外星这个属性去掉了,但是阿斯加德和泰坦星明显不是一个地球的城市,所以我们也要将城市属性换成NaN,但是分开设置又太麻烦了,我们就可以直接将城市作为一个映射的字典给替换掉。
这个时候外星这个属性去掉了,但是阿斯加德和泰坦星明显不是一个地球的城市,所以我们也要将城市属性换成NaN,但是分开设置又太麻烦了,我们就可以直接将城市作为一个映射的字典给替换掉。 处理完外星人的事了之后现在返回来处理咱们地球人的事,这个时候发现黑寡妇的生日是1929年,明显是一个假的出生日期,既然生日是假的年龄应该也是假的,所以我们需要将年龄更改为unknown,然后在定义为缺失值。
处理完外星人的事了之后现在返回来处理咱们地球人的事,这个时候发现黑寡妇的生日是1929年,明显是一个假的出生日期,既然生日是假的年龄应该也是假的,所以我们需要将年龄更改为unknown,然后在定义为缺失值。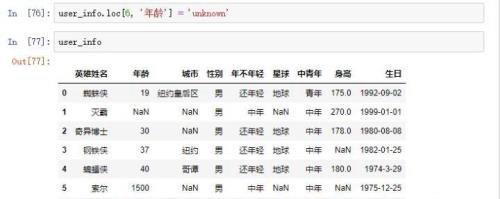
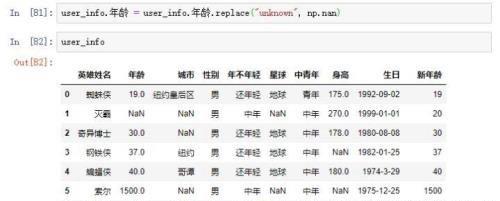
除了替换特定的值以外,我们还可以使用正则表达式来替换,如将空白字符串替换为空值。
将中年替换为中老年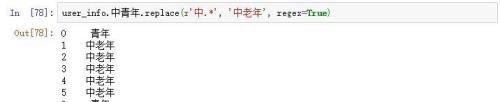
4、使用其他对象填充
除了我们自己手动丢弃、填充已经替换缺失值之外,我们还可以使用其他的对象来填充。
例如我们有两个用户年龄的series,其中一个由缺失值,另外一个没有,我们可以额将没有缺失值的series的元素传给有缺失值的。
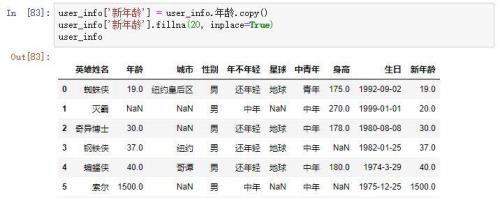
免责声明:本站部份内容由优秀作者和原创用户编辑投稿,本站仅提供存储服务,不拥有所有权,不承担法律责任。若涉嫌侵权/违法的,请反馈,一经查实立刻删除内容。本文内容由快快网络小婷创作整理编辑!