读写分离是什么(读写分离缺点)
导语:架构实战(5)——读写分离的那点事儿
什么是读写分离?
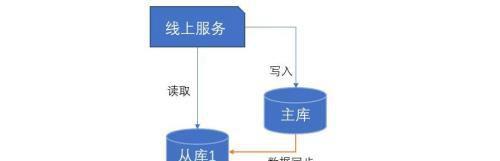
读写分离就是将数据库分为主库和从库,一个主库专用于写入数据,一个或多个从库用于读数据。主库和从库通过某种机制进行数据的同步。
读写分离能解决什么问题?
在互联网应用中,对数据库的操作普遍存在的问题是写少读多,数据的读取是性能瓶颈。通过引入从库,分担数据库读的压力,提升应用的并发访问能力。总结一下,读写分离解决的是数据库的读性能问题。
典型的应用场景:
主从库差异化的性能优化
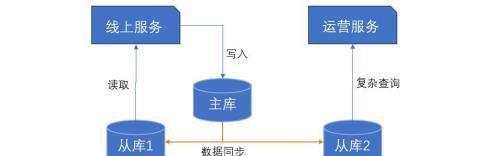
主从库采用不同的数据库引擎。Innodb是支持事务的,适合作为写库;而读库不需要事务,可使用MyISAM。主从库创建不同的索引。索引对可以提示读的性能,却会降低写的性能。可以在从库上创建差异化的索引,提升读性能。主从库差异性的参数优化。线上库和分析库的分离
很多互联网应用,一方面要在线上对客户提高可用的服务,另一方面也要满足线下运营部门的功能需求。线上的特点是查询简单、并发高;线下的特点是查询复杂、并发低。如果运营部门的查询需求,和线上应用一个从库,一些复杂的查询,就可能导致数据库的雪崩效应。针对这样的应用场景,提供两个从库,一个服务于线上,一个服务于线下,并根据不同的应用场景,做相应的优化。
延时备份
一般的做法是,创建一个延时从库,如果某个不小心的程序员,执行了一个删除命令,发现问题后,立即切断延时从库的同步,并且切换成主库,这样就能快速的恢复应用了。延时备份主要解决的是在发生故障的时候,能够快速恢复服务,并且尽量减少客户数据的丢失。

数据同步的原理是什么?
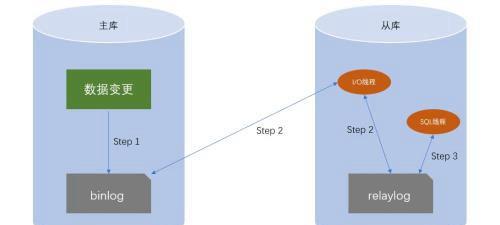 step1:主库的数据变动,逐条保存到binlog日志文件中。step2:从库的IO线程,读取主库的binlog日志文件,把binlog写入从库的relaylog日志文件中。step3:从库的SQL线程,读取已经同步过来的relaylog,逐条执行binlog,完成数据的同步。
step1:主库的数据变动,逐条保存到binlog日志文件中。step2:从库的IO线程,读取主库的binlog日志文件,把binlog写入从库的relaylog日志文件中。step3:从库的SQL线程,读取已经同步过来的relaylog,逐条执行binlog,完成数据的同步。从这个过程中可以看出,同步是异步的,即使网络的延迟非常小,主从库的同步无法避免延迟。另外,从库不能主动的去修改,只能从主库同步。
如何解决主从延迟?
正常的延迟应保持在100ms以内,20ms左右是比较理想的。但是,程序员用到主从库,心里就要有个意识,延迟随时可能发生,甚至会非常严重,在程序设计与开发的时候,要考虑到这个因素。
场景1:写后立即读。在一个请求中,写入数据后,立即数据库中读取数据。这种读的场景,写入和读取的时间间隔小于1ms,比正常的主从延迟时间更短,解决方案就是强制读主库。
场景2:读后写。这种典型场景就是insertOrUpdate,不存在插入,存在就更新。如果两个请求的时间间隔小于主从延迟的时间间隔,第二次的请求因为读不到,就会执行insert。当然可以用强制读主库的方式解决问题,但是这样增加了主库的读压力。正确的解决方案是分布式锁+缓存。
 step1:加分布式锁。防止同时对一条记录操作。step2:缓存中读数据。如果读到数据,执行step4。如果读不到数据,执行step3。step3:从库中读数据。step4:写库。step5:写缓存。设置缓存的有效期,缓存的有效期,即为允许的主从最大延迟时间。
step1:加分布式锁。防止同时对一条记录操作。step2:缓存中读数据。如果读到数据,执行step4。如果读不到数据,执行step3。step3:从库中读数据。step4:写库。step5:写缓存。设置缓存的有效期,缓存的有效期,即为允许的主从最大延迟时间。持续分享IT互联网相关的知识点,欢迎关注我。

免责声明:本站部份内容由优秀作者和原创用户编辑投稿,本站仅提供存储服务,不拥有所有权,不承担法律责任。若涉嫌侵权/违法的,请反馈,一经查实立刻删除内容。本文内容由快快网络小奈创作整理编辑!