分布式算法实现(分布式计算结构)
导语:理解分布式 Join 算法
动机
本文旨在帮助彻底厘清分布式 Join 算法的实现原理,以便深入研究分布式存储系统源码同时也有助于帮助业务进行 Join 相关的查询优化。
概念背景:
分布式系统情况下,数据通过分片分布在不同集群节点上。因此表数据如何在集群中分布是选择 Join 算法的关键因素。
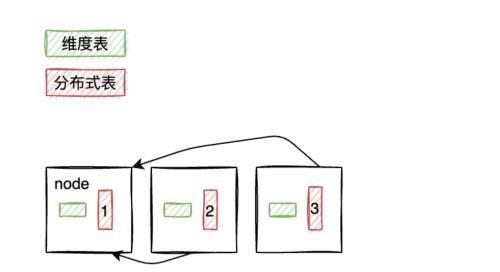
Local/Collocated Reference Table Join
场景:
将数据量少并且很少更新的维度表定义为 reference table,其常用于雪花模型。对于此类型的表可以将其复制到集群中的每一个节点。当其和分布式表(数据被分片到集群节点)进行 Join 的时候可以等价于在集群中每个节点执行 Local Join,然后将执行结果统一收集到集群中一个节点进行合并。
优点:
•可扩展性,不存在数据移动
缺点:
•需要调整 Schema,表需要提前被指定为 reference table•reference table 复制到集群中每一个节点,占用了更多磁盘内存空间
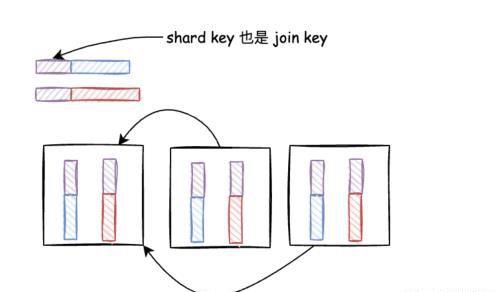
Local/Collocated Distributed Table Join
场景:
参与 Join 的表都按照 Join key 在集群进行数据分片,则每个节点都可以各自执行 Local Join,最终由一个节点收集结果进行合并。此场景是扩展性最好的,执行 Join 之前不涉及到数据的移动。
优点:
•可扩展性强,不存在数据移动
缺点:
•需要调整Schema,Shard keys 需要提前选择绑定。•灵活性差,大部分数据库只允许一个分片 key
Remote Distributed Table Join
场景:
Join 涉及的表数据量都特别少,则参与 Join 的两张表数据都可以被统一拉取到一个节点执行单机 Join 算法。集群所有节点都将涉及的到数据发送给统一节点进行处理。
优点:
•不需要改变 schema(例如 shard keys 或者 reference tables)•当涉及到的 join 数据量很小时具备一定的扩展性和很小的数据移动
缺点:
•只适用于 join 小数据量•涉及到大量数据在单一节点执行 join 时,性能非常不佳
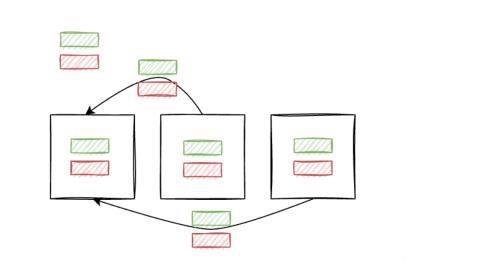
Broadcast Join
场景:
Join 涉及的一张表数据量很少(或者通过 where 选择)。较少的数据集被复制到集群的每个节点,然后每个节点分别执行 Local join,最后由一台机器汇总所有节点执行结果。此方法可以用 Local/Collocated Reference Table Join 理解,相当于在每个节点创建了临时的 Reference table。
优点:
•不需要改变 schema 结构(shard key 或 reference table)•灵活,使用于较多查询方式
缺点:
•仅当 join 的一侧包含很少数据量时才可行。•可扩展性较差,需要被广播的行需要被复制到集群的每个节点,在执行join之间涉及到大量节点的通信。
下图绿色1 2 3分片组合成一个完整的数据集。组合完成的绿色数据集可以看做临时reference table
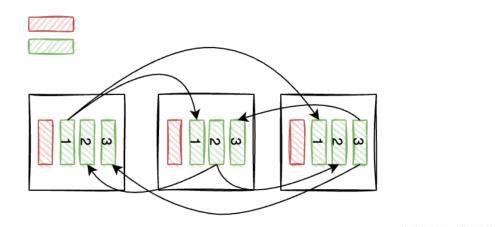
Reshuffle Join
场景:
Join 两侧都涉及到大量数据,采取 Broadcast Join 将在集群节点发送大量数据。这种情况下,最好先重新对数据进行分区,然后将分区数据发送给集群对应节点。
1.如果 join 一侧数据集 shard key 存在于 join key 中,则对另一侧数据选择同样的 shard key 进行分区
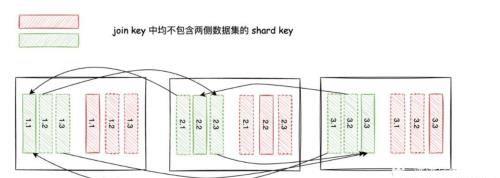
2.如果两侧数据数据的 shard key 都不存在 join key 中,则需要对两侧数据都按照 join key 进行重新分区。
优点:
•不需要改变schema
•非常灵活,适用于任何形式的查询类型
缺点:
•可扩展性最差,执行 join 之前需要涉及等价于 join 数据量的数据移动
高能预警:下图展示了每个节点绿色分区数据集重新分片后分片的分片移动的方向,省略了红色数据集的移动方向。1.1表示以前分区1重新分区之后的1分区,所有绿色分区组合成了完整的绿色数据集。
分布式 Join 优化
•将小且很少更新的数据表构建为 reference table,避免了后续 Join 过程中采取 broadcast 的方式移动它。
•尽可能的选择需要进行 join 的列进行数据分片。能让 local join 尽可能的执行,减少数据的移动量•Reshuffled Join 对于低并发的查询请求比较合理,其他情况应该尽量限制参与 Join 的数据量。
免责声明:本站部份内容由优秀作者和原创用户编辑投稿,本站仅提供存储服务,不拥有所有权,不承担法律责任。若涉嫌侵权/违法的,请反馈,一经查实立刻删除内容。本文内容由快快网络小涵创作整理编辑!