数据仓库中的两大经典模型是什么(数据仓库中的两大经典模型包括)
导语:数据仓库中的两大经典模型
在数据分析相关内容中,包括两大重要内容:一是底层数据系统建设内容,二是业务报表相关内容梳理。一是系统基础,二是基础之上的业务逻辑衍生。
在番茄风控之前的数据分析课程中,主要集中在以上的第二点即业务相关报表内容进行展开:


有童鞋跟我们交流,是否能稍微对第一种即底层基础的架构内容如数仓相关基础知识进行讲解?
今天跟大家介绍跟底层数据仓库建设方面的内容。类似数仓模型建设中,内容有关于明细模型、汇总模型、以及应用模型,然后在此基础上生成报表,辅助分析,引导规则或策略的制定等相关内容。
要了解关于底层数据仓库的内容中,就不得不提关于它的两大基础的底层数据模型,以下详细展开讲解。
在数据仓库的建设中,有两大基础模型分别是:星型模型和雪花模型,我们会围绕着两个模型来设计表关系或者结构。
1.图示—星型模型:
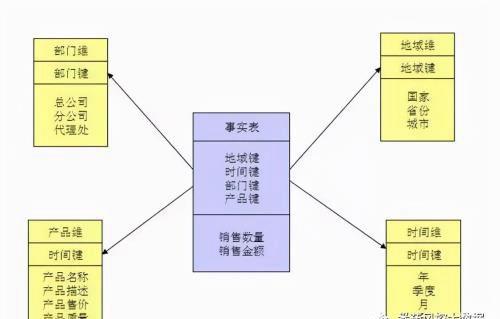
星型模型由一个事实表和一组维表组成,是一种多维的数据关系。里面的每个维表都有一个维作为主键,所有这些维的主键组合成事实表的主键。强调的是对维度进行预处理,将多个维度集合到一个事实表,形成一个宽表。所以在使用hive时,经常会看到一些大宽表的原因。
大宽表属于事实表,包含了维度关联的主键和度量信息,而维度表则是事实表里面维度的具体信息,使用时候一般通过join来组合数据,相对来说对OLAP的分析比较方便。
2.图示—雪花模型:
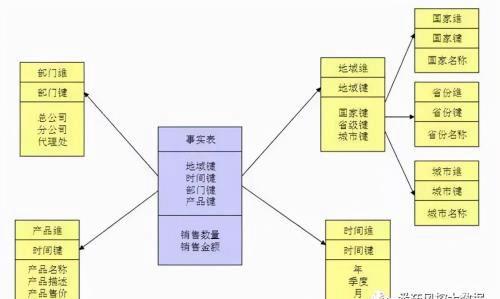
当在星型模型中,有一个或多个维表没有直接连接到事实表上时,而是通过其他维表连接到事实表上时,其图解就像多个雪花连接在一起,故称雪花模型。
雪花模型是对星型模型的扩展。也是对星型模型的维表进一步层次化,原有的各维表可能被扩展为小的事实表,形成一些局部的 区域,这些被分解的表都连接到主维度表而不是事实表。雪花模型更加符合数据库范式,减少数据冗余,但是在分析数据的时候,操作比较复杂,需要join的表比较多所以其性能并不一定比星型模型高。
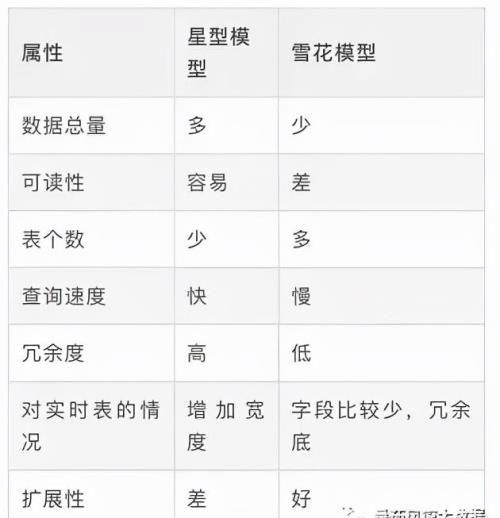
3.两大模型的优劣对比:
4.相关的场景应用
星型模型的设计方式主要带来的好处是能够提升查询效率。因为生成的事实表已经经过预处理,主要的数据都在事实表里面,所以只要扫描实时表就能够进行大量的查询,而不必进行大量的join,其次维表数据一般比较少,在join可直接放入内存进行join以提升效率,除此之外,星型模型的事实表可读性比较好,不用关联多个表就能获取大部分核心信息,设计维护相对比较简答。雪花模型的设计方式是比较符合数据库范式的理念,设计方式比较正规,数据冗余少,但在查询的时候可能需要join多张表从而导致查询效率下降,此外规范化操作在后期维护比较复杂。
5.小结
通过以上简单的比较,我们可以发现数据仓库大多数时候是比较适合使用星型模型构建底层数据Hive表,通过大量的冗余来提升查询效率,星型模型对OLAP的分析引擎支持比较友好。
目前而言,雪花模型在关系型数据库中如MySQL,Oracle中非常常见。在数据仓库中雪花模型的应用场景比较少,所以在具体设计的时候,可以考虑是不是能结合两者的优点参与设计,以此达到设计的最优化目的。除了本次的数仓的内容外,在即将安排上线的数据分析训练营的课程中,还迭代更新了spark相关的内容,详情如下:
1、spark简介
1.1、spark是什么
1.2、spark特性
1.3、spark安装
1.4、spark webui使用
1.5、spark-shell
1.6、idea开发spark
2、spark-core rdd核心概念
2.1、常用rdd算子操作
2.2、广播变量
2.3、依赖关系、血统、缓存、机制
2.4、调优总结
3、spark-sql
3.1、spark-sql特性
3.2、dataframe操作
3.3、dataset操作
3.4、自定义函数
3.5、spark-sql调优
4、spark-mlib
4.1、决策树
4.2、随机森林
5、spark案例:银行营销理财购买预测
5.1、数据集介绍
5.2、获取数据集
5.3、数据预处理和特征工程
5.4、选取特征数组
5.5、数据集划分
5.6、模型训练验证
详情可关注:《数据分析训练营》(另外还同步更新了二代征信实操模块内容):

~原创文章
...
end
免责声明:本站部份内容由优秀作者和原创用户编辑投稿,本站仅提供存储服务,不拥有所有权,不承担法律责任。若涉嫌侵权/违法的,请反馈,一经查实立刻删除内容。本文内容由快快网络小萱创作整理编辑!