上下文切换耗时(上下文切换会发生在哪些时间)
导语:上下文切换,你确定了解吗?
前言
听到上下文切换,大家第一反应肯定是:一定要减少这货出现的次数。确实上下文切换对性能的影响显而易见,但有时又无法完全避免,这就要求我们对上下文性能损耗了然于胸,才能更准确地评估系统性能。另外,现在云厂商提供的机器种类如此之多,虚拟机在这方面是否有区别。以上都需要有科学的方法来衡量上下文的耗时,进而帮助系统评估以及机型选择。
本文将从这以下两个方面来展开
上下文切换有哪些类型以及可能出现的场景衡量各场景上下文切换耗时1, 上下文切换类型及场景
上下文大体上可以分为两类
进程上下文中断上下文进程上下文具体包括:
(1)用户级上下文: 正文、数据、用户堆栈以及共享存储区;
(2)寄存器上下文: 通用寄存器、程序寄存器(IP)、处理器状态寄存器(EFLAGS)、栈指针(ESP);
(3)系统级上下文: 进程控制块task_struct、内存管理信息(mm_struct、vm_area_struct、pgd、pte)、内核栈。
中断上下文具体包括:
(1)硬件传递过来的参数
因此上下文切换可以分为以下几类:
(1)进程之间的上下文切换:A进程切换到B进程
(2)进程和中断之间的上下文切换:进程A被中断打断
(3)中断之间的上下文切换:低级别中断被高级别中断打断
其中第一种上下文切换最为常见,第二种次之,第三种最少见,因此本文接下来主要讨论前面两种上下文切换的耗时。
模式切换
这是要说一种特殊的上下文切换:模式切换,即进程A从用户态因为系统调用进入内核态,这种切换之所以特殊,是因为它并没有经过完整的上下文切换,只是寄存器上下文进行了切换,所以模式切换的耗时相对完整进程上下文更低。
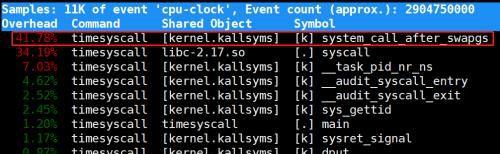
虽然模式切换较完整上下文切换耗少,但仍不能小觑,在物理机上,一次系统调用(以SYS_gettid为例)在50~60ns。(本文所有数据均是Intel(R) Xeon(R) V4和V5 CPU上得到)而在虚拟机上,一次系统调用更是可能达到
240ns ,从perf来看,system_call_after_swapgs函数消耗CPU较物理机多很多,网上有人说可能是为了解决Spectre漏洞,在每次系统调 用返回用户空间时,会清理一次BTB(branch target buffer),需要进一步确认。
1.png
因此,我们在代码里面也要尽量减少系统调用,常见的优化方法有:每次读写磁盘时,使用buffer减少read/write调用次数等。
2,上下文切换性能评估
测试上下文切换性能的工具有
unixbenchtsuna/contextswitch两个工具的原理类似,都是创建两个进程,然后互相唤醒:
(1) unixbench是创建两个进程,两个进程之间创建两个管道(pipe),通过管道来互相读写数据,结果是10s内完成的切换次数。
(2) contextswitch同样是创建两个进程,通过futex(快速用户区互斥)来互相唤醒,结果是循环500000次的耗时
进程之间的上下文切换
使用这两个工具在测试进程上下文时,需要注意一点:把两个进程绑定到同一个核上运行,否则可能测试的就不仅仅是进程上下文切换了,下面会介绍不绑核的情况。
unixbench
taskset -c 1 ./Run -c 1 context1
对于contextswitch
taskset -c 1 ./timectxsw
或者直接运行make或者./cpubench.sh
2.png
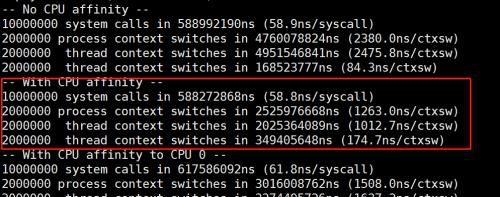
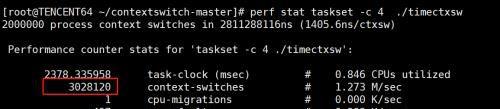
从上图可以看到,一次ctx的耗时在1012~1263ns ,但其实perf看,绑核情况下,运行timectxsw实际的ctx是在300w次(这里一次循环需要6次ctx),所以实际的ctx应该是674~842ns
3.png
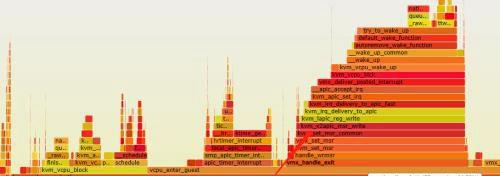
进程和中断上下文切换
上文提到如果要测试进程上下文切换耗时就一定要绑核,否则测试的很可能会包含进程和中断上下文切换的耗时,因为默认内核会把测试程序产生的进程调度到不同的核上,进程之间的唤醒,需要先发送IPI中断,对方CPU在收到IPI中断之后,会完成一次中断上下文切换,执行中断函数,进而再唤醒相应进程。所以在不绑核的情况下,测试的就包含了进程-中断上下文以及中断处理函数的耗时。

4.png
unixbench
如果使用unixbench在腾讯云上,默认调度到1个核上,这样就测试的进程上下文切换,所以需要手动修改代码绑核,或者用git上的unixbench-fix,强制将两个进程放到不同的核上

5.png
contextswitch
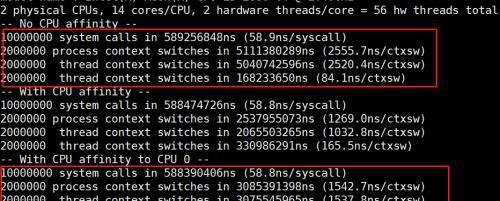
contextswitch这里还增加了在同一个NUMA上的测试,从测试数据看,两个进程如果调度到同一个NUMA上时,耗时会更短。
6.png
从测试数据看:
如果两个进程跨NUMA,一次上下文切换的耗时在2500ns如果两个进程在同NUMA,一次上下文切换的耗时在1500ns在虚拟机里面,跨核的上下文切换会更大,因为vcpu无法处理IPI中断,需要退出的宿主机上处理,从而增加了上下文切换的耗时,总体上虚拟机跨核ctx的耗时是宿主机的2~3倍。
下一篇文章我们会对IPI中断的测试方法以及虚拟化之后可能的优化方法进行介绍,欢迎订阅,及时查看。
上下文
免责声明:本站部份内容由优秀作者和原创用户编辑投稿,本站仅提供存储服务,不拥有所有权,不承担法律责任。若涉嫌侵权/违法的,请反馈,一经查实立刻删除内容。本文内容由快快网络小开创作整理编辑!