聚类分析方法介绍(聚类分析算法基本原理)
导语:“机器学习”技术之聚类分析概述和常用方法总结
今天给大家概述一下机器学习中经常用到的一个技术—聚类分析,使大家对聚类分析有一个全面大致的了解。
聚类分析介绍
聚类是数据挖掘的重要工具,根据数据间的相似性将数据分成多个类,每类中数据应尽可能相似。从机器学习的观点来看,类相当于隐藏模式,寻找类是无监督学习过程
聚类算法通常有分层聚类、分割聚类、基于密度的聚类、基于栅格的聚类、字符属性联合聚类、高维数据聚类和神经网络聚类等
在聚类算法选择时,不仅要考虑所要处理的数据属性的种类,也要考虑算法的抗干扰性和时间复杂度等

聚类分析
聚类分析的过程
数据预处理——标准化
构造关系/距离矩阵——亲疏关系的描述
聚类——根据不同方法进行聚类
确定最佳分类——类别数
数据预处理
指标变量的量纲不同或数量级相差很大,为了使这些数据能放到一起加以比较,常需做变换。
Z-Scores标准化变换

Z-Scores标准化变换
Range –1 to 1:极差标准化变换
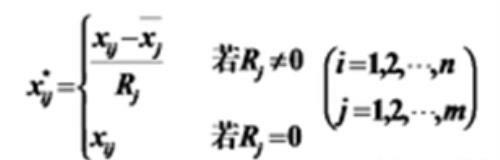
极差标准化变换
Range 0 to 1:极差正规化变换 / 规格化变换

极差正规化变换 / 规格化变换
Mean of 1:均值为1
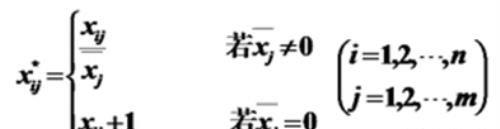
均值为1
Standard deviation of 1:方差为1

方差为1
构造关系/距离矩阵
欧氏(Euclidean)距离
未考虑指标间的相关性和各变量方差的不同。
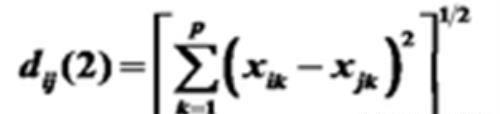
欧氏(Euclidean)距离
切比雪夫(Chebychev)距离
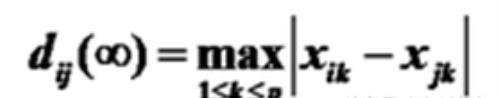
切比雪夫(Chebychev)距离
明氏(Minkowski)距离
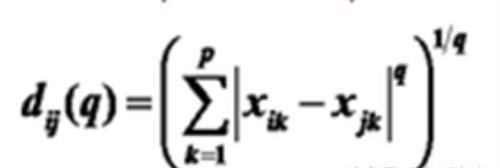
明氏(Minkowski)距离
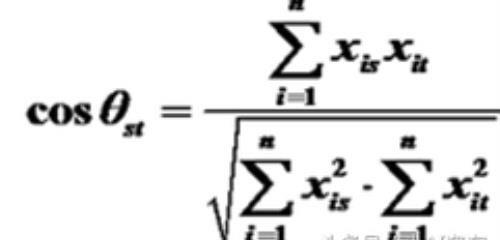
夹角余弦

夹角余弦
Pearson相关系数
Pearson相关系数
Block:绝对值距离
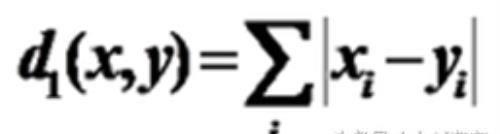
绝对值距离
聚类方法的选择
层次聚类/谱系聚类
K-Means聚类、K-Medoids聚类
模糊聚类、图论聚类、SOM聚类等
感兴趣的读者可以阅读作者之前写的文章了解详细内容和具体案例。
《常用数据挖掘算法从入门到精通 第二章 K-means聚类算法》
《常用数据挖掘算法从入门到精通 第三章 K-中心点聚类算法》
《常用数据挖掘算法从入门到精通 第四章SOM神经网络聚类(上)》
《常用数据挖掘算法从入门到精通 第四章SOM神经网络聚类(下)》
聚类个数的确定
任何类都必须在临近各类中是突出的,即各类重心间距离必须极大
确定的类中,各类所包含的元素都不要过分地多
分类的数目必须符合实际使用目的
若采用几种不同的聚类方法处理,则在各自的聚类图中应发现相同的类
免责声明:本站部份内容由优秀作者和原创用户编辑投稿,本站仅提供存储服务,不拥有所有权,不承担法律责任。若涉嫌侵权/违法的,请反馈,一经查实立刻删除内容。本文内容由快快网络小悦创作整理编辑!